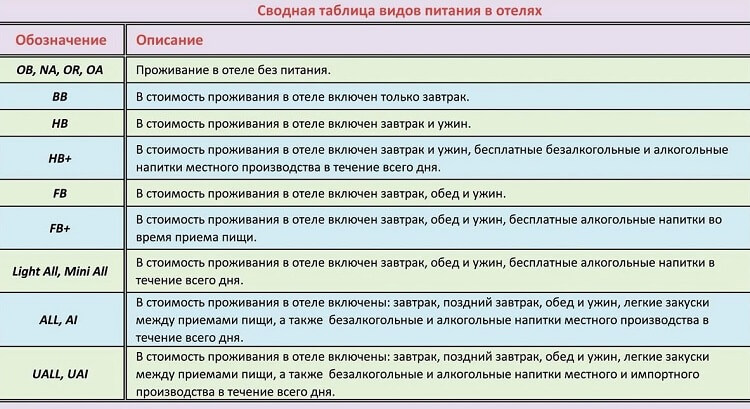
Что означает аи: Что обозначают марки бензина и основные свойства АИ-80, АИ-92, АИ-95, АИ-98
Что означают буквы АИ в названии бензина? | Об автомобилях | Авто
Владимир Гаврилов
Примерное время чтения: 3 минуты
45909
Категория: Авто
Сорта бензина маркируются по-разному. Раньше были распространены топлива под названием А-55, А-72, А-76, А-80 и т. д. С начала 90-х годов прошлого века их место заняли другие сорта, обозначающиеся аббревиатурами: АИ-91, АИ-92, АИ-93, АИ-95, АИ-98. И если цифры в этих кодах соответствуют октановому числу топлива, то буквы определяют сорт бензина, его предназначение и тип сертификации.
Бензин для грузовиков
Октановое число характеризует детонационную стойкость бензина, от которой зависит способность топлива сопротивляться детонациям на пиковых нагрузках при работе двигателя. Однако октановое число — это не стандартная величина, а относительная. Она определяется различными методами, в зависимости от которых меняется и само октановое число.
Она определяется различными методами, в зависимости от которых меняется и само октановое число.
Первый способ принято называть моторным.
Для определения октанового числа в этом случае используется специальные одноцилиндровые лабораторные установки УИТ-65 или УИТ-85 с изменяемой степенью сжатия в камере сгорания.
Мотор раскручивают до 900 оборотов на исследуемом топливе при температуре всасываемой смеси 149 гр. Цельсия и с переменным углом опережения зажигания. Этот характер работы мотора больше похож на специфику эксплуатации грузовых машин. Нагрузка всегда высока, но обороты мотора изменяются несильно. Примерно так же мотор работает, когда машина идет с грузом в гору при частичном дроссельном ускорении. До 80-х годов прошлого века бензины разрабатывались в основном для грузовиков, и октановое число определялось моторным способом. Такие сорта бензина имели в названии литеру А, то есть «автомобильный» (А-72, А-76, А-80).
Бензин для легковых машин
С развитием легкового транспорта понадобились сорта бензина для небольших малолитражных моторов.
Этот метод определения октанового числа называют исследовательским. Моторная одноцилиндровая установка с переменной степенью сжатия раскручивает коленчатый вал до 600 об/мин при температуре всасываемого воздуха в 52 гр. Цельсия и угле опережения зажигания 13 гр. Тем самым воспроизводятся малые и средние нагрузки.
В государственном стандарте для сортов топлива, разработанных специально для использования на легковых машинах, к букве «А» (автомобильный) добавилась еще одна литера «И», которая указывает на исследовательский метод определения октанового числа (ОЧ).
Тем самым АИ-92 расшифровывается как автомобильный бензин с ОЧ 92, определенный по исследовательскому методу.
Между тем код АИ далеко не единственный. Существуют и иные маркировки бензина.
Сорта российских авиационных бензинов маркируются по ГОСТ 1012-72 как Б-91/115 и Б-95/130, где Б — бензин, а цифры — это октановые числа при обедненной и обогащенной смесях.
В нефтяной промышленности применяются также технологические бензины БР-1 и БР-2, где БР — это бензин-растворитель.
бензинсорта
Следующий материал
Новости СМИ2
Почему на бензине пишут Аи
Прочее › Находится › Что не находится в индивидуальной аптечке аи 2
Аббревиатура «АИ» расшифровывается следующим образом: буква «А» означает, что топливо предназначено только для автотранспорта буква «И» — это информация о том, что октановое число было проверено в лаборатории исследовательским методом
- Что означают буквы АИ в марке бензина
- Почему АИ 95
- Почему АИ 92
- Что означает АИ 92 бензин
- Что такое бензин АИ 92 к5
- Чем бензин АИ 80 отличается от АИ 92
- Что будет если перемешать АИ 92 и АИ 95
- Можно ли использовать АИ 95 вместо АИ 92
- Что такие АИ
- Что значит АИ 80
- Что такое АИ 95 к5
- Что означают цифры в маркировке бензина А 76 Аи 93)
- Какой экологический класс у нефтепродукта АИ 92 к5
- Что означает числовой индекс в маркировке бензина АИ 95
Что означают буквы АИ в марке бензина
АИ — маркировка бензина (автомобильного топлива), октановое число которого определено по исследовательскому методу АИ — агроинженерия АИ — апоптотический индекс
Почему АИ 95
Например, АИ-95 — топливо для автомобилей (заправить самолет им точно не получится), имеющее октановое число 95, и это проверено исследовательским методом. Октановое число — основной показатель детонационной стойкости бензина. Чем выше цифра, тем лучше бензин противостоит самопроизвольному воспламенению.
Октановое число — основной показатель детонационной стойкости бензина. Чем выше цифра, тем лучше бензин противостоит самопроизвольному воспламенению.
Почему АИ 92
Расшифровка АИ-92 означает, что это бензин автомобильный (буква А), октановое число которого (ОЧ 92) было рассчитано исследовательским методом (буква И) в условиях, максимально соответствующих стандартным городским. Многие считают, что более высокая цифра октанового числа говорит о лучшем качестве топлива.
Что означает АИ 92 бензин
Разница в качестве АИ-92 и АИ-95
Буква «А» в маркировке означает, что топливо подходит для автотранспортных средств, «И» — бензин исследован на октановое число в специализированном центре. 92 и 95 — это октановые числа, определяющие стойкость горючего материала к детонации.
Что такое бензин АИ 92 к5
Марка топлива АИ-92-К5 означает автомобильный бензин, который имеет октановое число 92 и относится к экологическому классу К5, то есть содержит серу в количестве 10,0 мг/ кг.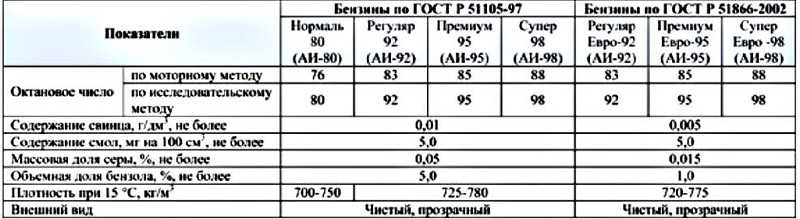 Данная марка бензина является самой распространенной и востребованной на территории РФ.
Данная марка бензина является самой распространенной и востребованной на территории РФ.
Чем бензин АИ 80 отличается от АИ 92
АИ-80 — с октановым числом по исследовательскому методу не менее 80. АИ-92 — с октановым числом по исследовательскому методу не менее 92; для двигателей со степенью сжатия до 10.5. АИ-95 — с октановым числом по исследовательскому методу не менее 95; для двигателей со степенью сжатия 10.5-12.
Что будет если перемешать АИ 92 и АИ 95
Вывод Так можно ли смешивать 92-й и 95-й бензин? Если в АИ-92 добавить АИ-95, ничего страшного не произойдет, а вот в обратную сторону (добавить в 95-й) — тоже можно, но нечасто. От пары раз такого смешивания вреда не будет, но если злоупотреблять, это может привести к ухудшению работы двигателя.
Можно ли использовать АИ 95 вместо АИ 92
Смешивается ли бензин 92 с 95? Ответ: нет. Происходит следующее: 95-я марка является более легкой, поэтому ее слой будет собираться в верхней части 92-го бензина, имеющего увеличенную плотность. В процессе работы силового агрегата сначала вырабатывается одна разновидность горючего, а затем вторая.
В процессе работы силового агрегата сначала вырабатывается одна разновидность горючего, а затем вторая.
Что такие АИ
Искусственный интеллект (AI) — раздел информатики, который занимается решением когнитивных задач, обычно предназначаемых для человеческого интеллекта, таких как обучение, решение проблем и распознавание шаблонов.
Что значит АИ 80
Бензин АИ-80 относят к неэтилированным автомобильным бензинам. Данный продукт получают в процессе возгонки нефти при производстве различных нефтепродуктов. Стандартный состав топлива аи 80 — это молекула от С5 до С10. Полное название этого продукта — «бензин нормаль АИ-80», где «80» — это октановое число.
Что такое АИ 95 к5
Например, марка бензина будет обозначаться так: АИ-95-К5, где буквы АИ обозначают автомобильный бензин, 95 — цифровое обозначение октанового числа автомобильного бензина, определенного исследовательским методом, а символы К5 обозначают экологический класс топлива.
Что означают цифры в маркировке бензина А 76 Аи 93)
Разные цифры в маркировке объясняются просто: 80 — это октановое число, измеренное исследовательским методом, а 76 — это же октановое число, но после проведения моторного тестирования.
Какой экологический класс у нефтепродукта АИ 92 к5
БЕНЗИН НЕЭТИЛИРОВАННЫЙ. МАРКА АИ-92. ЭКОЛОГИЧЕСКИЙ КЛАСС К5, АИ-92-К5.
Что означает числовой индекс в маркировке бензина АИ 95
Всем знакомые индексы А-76, АИ-80, АИ-92, АИ-95 и АИ-98 — это марки бензина. Значение октанового числа (именно его обозначает цифра в индексе) указывает на такое свойство, как стойкость бензина к детонации. Цифра эта относительная.
Что такое глубокое обучение и как оно работает?
Вы когда-нибудь задумывались, как Google может переводить целые абзацы с одного языка на другой за миллисекунды? как Netflix и YouTube могут дать хорошие рекомендации; как вообще возможны беспилотные автомобили?
Все эти инновации являются продуктом глубокого обучения и искусственных нейронных сетей.
Что такое глубокое обучение и как оно работает?
Глубокое обучение — это просто тип машинного обучения, вдохновленный структурой человеческого мозга. Алгоритмы глубокого обучения пытаются делать такие же выводы, как и люди, постоянно анализируя данные с заданной логической структурой. Для этого в глубоком обучении используются многоуровневые структуры алгоритмов, называемые нейронными сетями.
Для этого в глубоком обучении используются многоуровневые структуры алгоритмов, называемые нейронными сетями.
Ого. . . Резервное копированиеИскусственный интеллект, машинное обучение и глубокое обучение
Что такое глубокое обучение?
Глубокое обучение — это подмножество машинного обучения, которое является подмножеством искусственного интеллекта. Искусственный интеллект — это общий термин, который относится к методам, позволяющим компьютерам имитировать поведение человека. Машинное обучение представляет собой набор алгоритмов, обученных на данных, которые делают все это возможным. Глубокое обучение — это всего лишь тип машинного обучения, вдохновленный структурой человеческого мозга.
ИИ против машинного обучения против глубокого обучения Алгоритмы глубокого обучения пытаются делать такие же выводы, как и люди, постоянно анализируя данные с заданной логической структурой. Для этого в глубоком обучении используется многоуровневая структура алгоритмов, называемых нейронными сетями.
Дизайн нейронной сети основан на структуре человеческого мозга. Точно так же, как мы используем наш мозг для выявления закономерностей и классификации различных типов информации, мы можем научить нейронные сети выполнять те же задачи с данными.
Отдельные слои нейронных сетей также можно рассматривать как своего рода фильтр, который работает от грубого к тонкому, что увеличивает вероятность обнаружения и вывода правильного результата. Аналогично работает человеческий мозг. Всякий раз, когда мы получаем новую информацию, мозг пытается сравнить ее с известными объектами. Та же концепция используется и в глубоких нейронных сетях.
Нейронные сети позволяют нам выполнять множество задач, таких как кластеризация, классификация или регрессия.
С помощью нейронных сетей мы можем группировать или сортировать неразмеченные данные в соответствии со сходством выборок в данных. Или, в случае классификации, мы можем обучить сеть на размеченном наборе данных, чтобы классифицировать выборки в наборе данных по разным категориям.
В целом, нейронные сети могут выполнять те же задачи, что и классические алгоритмы машинного обучения (но классические алгоритмы не могут выполнять те же задачи, что и нейронные сети). Другими словами, искусственные нейронные сети обладают уникальными возможностями, которые позволяют моделям глубокого обучения решать задачи, которые модели машинного обучения никогда не решают.
Все последние достижения в области искусственного интеллекта в последние годы связаны с глубоким обучением. Без глубокого обучения у нас не было бы беспилотных автомобилей, чат-ботов или личных помощников, таких как Alexa и Siri. Google Translate останется таким же примитивным, как и 10 лет назад, до того, как Google переключился на нейронные сети, а Netflix не будет знать, какие фильмы предлагать. За всеми этими технологиями стоят нейронные сети.
Происходит новая промышленная революция, движимая искусственными нейронными сетями и глубоким обучением. В конце концов, глубокое обучение — это лучший и наиболее очевидный подход к реальному машинному интеллекту, который у нас когда-либо был.
Еще от ArtemКак ИИ обучает себя с помощью глубокого обучения с подкреплением
Почему глубокое обучение популярно?
Модели глубокого обучения более эффективны, чем модели машинного обучения, но почему?
Нет выделения признаков
Первым преимуществом глубокого обучения перед машинным обучением является избыточность так называемого выделения признаков.
Задолго до того, как мы начали использовать глубокое обучение, мы полагались на традиционные методы машинного обучения, включая деревья решений, SVM, наивный байесовский классификатор и логистическую регрессию. Эти алгоритмы также называются плоскими алгоритмами. «Плоский» здесь относится к тому факту, что эти алгоритмы обычно нельзя применять непосредственно к необработанным данным (таким как .csv, изображения, текст и т. д.). Нам нужен шаг предварительной обработки, называемый извлечением признаков.
Результатом извлечения признаков является представление исходных данных, которые эти классические алгоритмы машинного обучения могут использовать для выполнения задачи. Например, теперь мы можем классифицировать данные по нескольким категориям или классам. Извлечение признаков обычно довольно сложно и требует детального знания предметной области. Этот уровень предварительной обработки должен быть адаптирован, протестирован и улучшен в течение нескольких итераций для получения оптимальных результатов.
Например, теперь мы можем классифицировать данные по нескольким категориям или классам. Извлечение признаков обычно довольно сложно и требует детального знания предметной области. Этот уровень предварительной обработки должен быть адаптирован, протестирован и улучшен в течение нескольких итераций для получения оптимальных результатов.
Искусственные нейронные сети глубокого обучения не нуждаются в этапе извлечения признаков. Слои могут изучать неявное представление необработанных данных напрямую и самостоятельно.
Вот как это работает: все более и более абстрактное и сжатое представление необработанных данных создается на нескольких слоях искусственной нейронной сети. Затем мы используем это сжатое представление входных данных для получения результата. Результатом может быть, например, классификация входных данных по разным классам.
Извлечение признаков требуется только для алгоритмов машинного обучения Другими словами, можно сказать, что этап выделения признаков уже является частью процесса, происходящего в искусственной нейронной сети.
В процессе обучения эта нейронная сеть оптимизирует этот шаг, чтобы получить наилучшее абстрактное представление входных данных. Это означает, что модели глубокого обучения практически не требуют ручных усилий для выполнения и оптимизации процесса извлечения признаков.
Давайте рассмотрим конкретный пример. Если вы хотите использовать модель машинного обучения, чтобы определить, показывает ли конкретное изображение автомобиль или нет, нам, людям, сначала нужно определить уникальные характеристики автомобиля (форма, размер, окна, колеса и т. д.), а затем извлечь функцию и передать ее алгоритму в качестве входных данных. Таким образом, алгоритм будет выполнять классификацию изображений. То есть в машинном обучении программист должен вмешиваться непосредственно в действие, чтобы модель пришла к выводу.
В случае модели глубокого обучения шаг извлечения признаков совершенно не нужен. Модель будет распознавать эти уникальные характеристики автомобиля и делать правильные прогнозы без вмешательства человека.
На самом деле воздержание от извлечения характеристик данных применимо к любой другой задаче, которую вы когда-либо выполняли с помощью нейронных сетей. Просто отправьте необработанные данные в нейронную сеть, а модель сделает все остальное.
Эпоха больших данных
Второе огромное преимущество глубокого обучения и ключевая часть понимания того, почему оно становится таким популярным, заключается в том, что оно основано на огромных объемах данных. Эпоха больших данных предоставит огромные возможности для новых инноваций в области глубокого обучения. Но не верьте мне на слово Эндрю Нг, главный научный сотрудник крупнейшей поисковой системы Китая Baidu, соучредитель Coursera и один из руководителей проекта Google Brain Project, выразился так:
Я думаю, что ИИ — это похоже на постройку ракеты. Вам нужен огромный двигатель и много топлива. Если у вас большой двигатель и небольшое количество топлива, вы не доберетесь до орбиты. Если у вас крошечный двигатель и тонна топлива, вы даже не сможете взлететь. Чтобы построить ракету, вам нужен огромный двигатель и много топлива.
Чтобы построить ракету, вам нужен огромный двигатель и много топлива.
Аналогия с глубоким обучением заключается в том, что ракетный двигатель — это модели глубокого обучения, а топливо — огромные объемы данных, которые мы можем передать этим алгоритмам.
Алгоритмы глубокого обучения улучшаются с увеличением объема данных.Модели глубокого обучения, как правило, повышают свою точность с увеличением объема обучающих данных, тогда как традиционные модели машинного обучения, такие как SVM и наивный байесовский классификатор, перестают улучшаться после точки насыщения.
Встроенный совет по карьере для начинающих технических специалистов Наука о данных и машинное обучение: в чем разница?
Как работают нейронные сети с глубоким обучением?
Биологические нейронные сети Искусственные нейронные сети созданы на основе биологических нейронов нашего мозга. Фактически, искусственные нейронные сети имитируют некоторые основные функции биологической нейронной сети, но очень упрощенно. Давайте сначала посмотрим на биологические нейронные сети, чтобы провести параллели с искусственными нейронными сетями.
Давайте сначала посмотрим на биологические нейронные сети, чтобы провести параллели с искусственными нейронными сетями.
Короче говоря, биологическая нейронная сеть состоит из множества нейронов.
Модель биологической нейронной сетиТипичный нейрон состоит из тела клетки, дендритов и аксона. Дендриты представляют собой тонкие структуры, выходящие из тела клетки. Аксон представляет собой клеточное расширение, которое выходит из тела этой клетки. Большинство нейронов получают сигналы через дендриты и посылают сигналы по аксону.
В большинстве синапсов сигналы переходят от аксона одного нейрона к дендриту другого. Все нейроны электрически возбудимы благодаря поддержанию градиента напряжения в их мембранах. Если напряжение изменяется на достаточно большую величину за короткий промежуток времени, нейрон генерирует электрохимический импульс, называемый потенциалом действия. Этот потенциал быстро распространяется по аксону и активирует синаптические связи.
Искусственные нейронные сети
Теперь, когда у нас есть общее представление о том, как функционируют биологические нейронные сети, давайте взглянем на архитектуру искусственной нейронной сети.
Нейронная сеть обычно состоит из набора связанных блоков или узлов. Мы называем эти узлы нейронами. Эти искусственные нейроны слабо моделируют биологические нейроны нашего мозга.
Искусственная нейронная сеть с прямой связью Нейрон — это просто графическое представление числового значения (например, 1,2 , 5,0 , 42,0 , 0,25 и т. д.). Любое соединение между двумя искусственными нейронами можно считать аксоном в биологическом мозге. Связи между нейронами реализуются так называемыми весами, которые также представляют собой не что иное, как числовые значения.
Когда искусственная нейронная сеть обучается, веса между нейронами меняются, как и сила связи. Что это значит? Учитывая данные обучения и конкретную задачу, такую как классификация чисел, мы ищем определенные заданные веса, которые позволяют нейронной сети выполнять классификацию.
Набор весов различен для каждой задачи и каждого набора данных. Мы не можем заранее предсказать значения этих весов, но нейронная сеть должна их узнать. Процесс обучения — это то, что мы называем обучением.
Мы не можем заранее предсказать значения этих весов, но нейронная сеть должна их узнать. Процесс обучения — это то, что мы называем обучением.
Произошла ошибка.
Невозможно выполнить JavaScript. Попробуйте посмотреть это видео на сайте www.youtube.com или включите JavaScript, если он отключен в вашем браузере.
Что такое глубокое обучение? Основы, введение и обзор | Видео: Лекс Фридман, MIT
Архитектура нейронной сети глубокого обучения
Типичная архитектура нейронной сети состоит из нескольких уровней; мы называем первый входным слоем.
Входной слой получает ввод x , (т.е. данные, на которых обучается нейронная сеть). В нашем предыдущем примере классификации рукописных чисел эти входные данные 90 117 x 90 118 будут представлять изображения этих чисел (90 117 x 90 118 — это, по сути, целый вектор, где каждая запись — это пиксель).
Входной слой имеет столько же нейронов, сколько записей в векторе x . Другими словами, каждый входной нейрон представляет один элемент вектора.
Другими словами, каждый входной нейрон представляет один элемент вектора.
Последний слой называется выходным слоем, который выводит вектор y , представляющий результат нейронной сети. Записи в этом векторе представляют значения нейронов в выходном слое. В нашей классификации каждый нейрон последнего слоя представляет отдельный класс.
В этом случае значение выходного нейрона дает вероятность того, что рукописная цифра, заданная признаками x , принадлежит к одному из возможных классов (одна из цифр 0-9 ). Как вы понимаете, количество выходных нейронов должно быть таким же, как и классов.
Чтобы получить прогнозный вектор y , сеть должна выполнить определенные математические операции, которые она выполняет в слоях между входным и выходным слоями. Мы называем их скрытыми слоями. Теперь давайте обсудим, какие связи между слоями выглядят так.
Дополнительные руководства по встроенной технологии НЛП для начинающих: полное руководство
Связи слоев в нейронной сети с глубоким обучением
Рассмотрим нейронную сеть меньшего размера, состоящую всего из двух слоев. Входной слой имеет два входных нейрона, а выходной слой состоит из трех нейронов.
Соединения слоевКак упоминалось ранее, каждое соединение между двумя нейронами представлено числовым значением, которое мы называем весом.
Как вы можете видеть на рисунке, каждое соединение между двумя нейронами представлено разным весом w . Каждый из этих весов w имеет индексы. Первое значение индексов соответствует количеству нейронов в слое, из которого происходит соединение, второе значение — количеству нейронов в слое, к которому ведет соединение.
Все веса между двумя слоями нейронной сети могут быть представлены матрицей, называемой матрицей весов.
Весовая матрица Весовая матрица имеет столько записей, сколько связей между нейронами. Размеры весовой матрицы определяются размерами двух слоев, которые связаны этой весовой матрицей.
Размеры весовой матрицы определяются размерами двух слоев, которые связаны этой весовой матрицей.
Количество строк соответствует количеству нейронов в слое, из которого исходят соединения, а количество столбцов соответствует количеству нейронов в слое, к которому ведут соединения.
В этом конкретном примере количество строк весовой матрицы соответствует размеру входного слоя, который равен двум, а количество столбцов — размеру выходного слоя, который равен трем.
Еще от Artem5 Функции активации глубокого обучения, которые необходимо знать
Изучение процесса нейронной сети глубокого обучения
Теперь, когда мы лучше понимаем архитектуру нейронной сети, мы можем лучше изучить процесс обучения. Давайте сделаем это шаг за шагом. Вы уже знаете первый шаг. Для данного входного вектора признаков x нейронная сеть вычисляет вектор предсказания, который мы называем h .
Мы также называем этот шаг прямым распространением.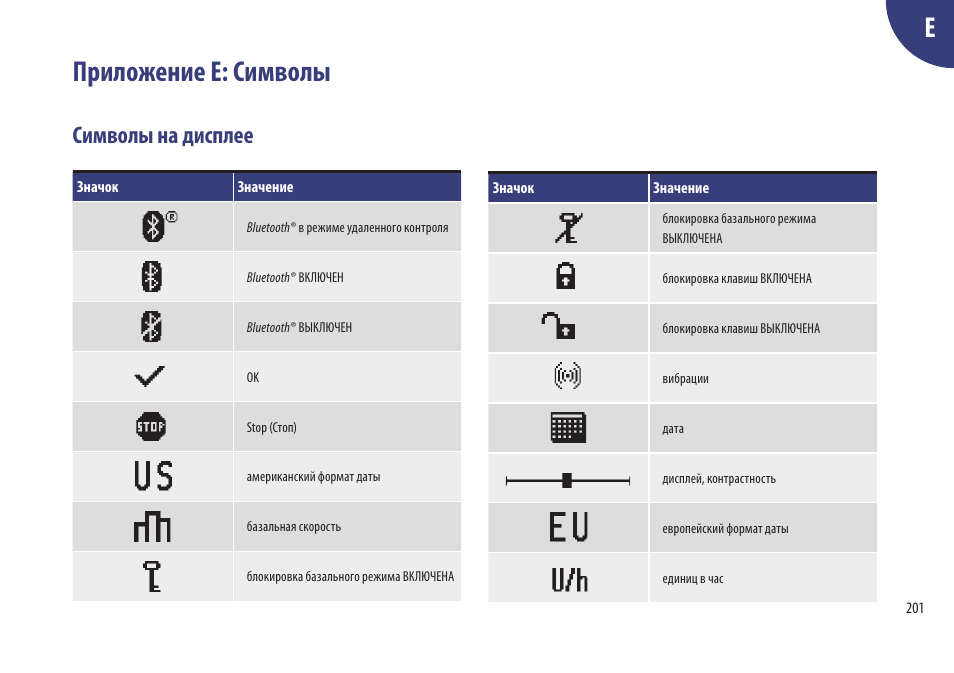 С входным вектором
С входным вектором x и матрица весов W , соединяющая два слоя нейронов, мы вычисляем скалярное произведение между вектором x и матрицей W .
Результатом этого скалярного произведения является другой вектор, который мы называем z .
Мы получаем окончательный вектор предсказания h , применяя так называемую функцию активации к вектору z . В этом случае функция активации представлена буквой сигма .
Функция активации — это нелинейная функция, выполняющая нелинейное отображение от z до h .
В глубоком обучении мы используем три функции активации: tanh, sigmoid и ReLu.
На этом этапе вы можете распознать значение нейронов в нейронной сети: просто представление числового значения. Давайте на мгновение взглянем на вектор z поближе.
Как видите, каждый элемент z состоит из входного вектора x . В этот момент роль весов раскрывается красиво. Значение нейрона в слое состоит из линейной комбинации значений нейронов предыдущего слоя, взвешенных некоторыми числовыми значениями.
В этот момент роль весов раскрывается красиво. Значение нейрона в слое состоит из линейной комбинации значений нейронов предыдущего слоя, взвешенных некоторыми числовыми значениями.
Эти числовые значения являются весами, которые говорят нам, насколько сильно эти нейроны связаны друг с другом.
Во время тренировки эти веса регулируются; некоторые нейроны становятся более связанными, в то время как некоторые нейроны становятся менее связанными. Как и в биологической нейронной сети, обучение означает изменение веса. Соответственно значения z , h и конечный выходной вектор y изменяются вместе с весами. Некоторые веса делают прогнозы нейронной сети ближе к реальному вектору истинности y_hat ; другие веса увеличивают расстояние до истинного вектора земли.
Теперь, когда мы знаем, как выглядят математические вычисления между двумя слоями нейронной сети, мы можем расширить наши знания на более глубокую архитектуру, состоящую из пяти слоев.
Как и раньше, мы вычисляем скалярное произведение между входными x и первую матрицу весов W1 , и примените функцию активации к результирующему вектору, чтобы получить первый скрытый вектор h2 . Теперь мы считаем h2 входными данными для предстоящего третьего слоя. Мы повторяем всю процедуру до тех пор, пока не получим окончательный результат y :
Функции потерь в глубоком обучении
После того, как мы получим прогноз нейронной сети, мы должны сравнить этот вектор прогноза с фактическая наземная этикетка истины. Мы называем вектором метки наземной истины у_шляпа .
В то время как вектор y содержит прогнозы, вычисленные нейронной сетью во время прямого распространения (которые на самом деле могут сильно отличаться от фактических значений), вектор y_hat содержит фактические значения.
Математически мы можем измерить разницу между y и y_hat , определив функцию потерь, значение которой зависит от этой разницы.
Примером общей функции потерь является квадратичная функция потерь:
Квадратичные потери Значение этой функции потерь зависит от разницы между y_hat и y . Более высокая разница означает более высокое значение потерь, а меньшая разница означает меньшее значение потерь.
Минимизация функции потерь напрямую приводит к более точным прогнозам нейронной сети, так как разница между прогнозом и меткой уменьшается.
Минимизация функции потерь автоматически приводит к тому, что модель нейронной сети делает более точные прогнозы независимо от точных характеристик поставленной задачи. Вам нужно только выбрать правильную функцию потерь для задачи.
К счастью, есть только две функции потерь, о которых вы должны знать, чтобы решить практически любую проблему, с которой вы сталкиваетесь на практике: потери кросс-энтропии и потери среднеквадратичной ошибки (MSE).
Потеря кросс-энтропии Функция потери кросс-энтропии
Потеря среднего квадрата ошибки Функция потери среднего квадрата ошибки
при котором значение функции потерь является как можно меньшим. Метод минимизации функции потерь достигается математически с помощью метода, называемого градиентным спуском.
Подробнее о функциях потерь Думаете, вам не нужны функции потерь в глубоком обучении? Подумайте еще раз.
Градиентный спуск в глубоком обучении
Во время градиентного спуска мы используем градиент функции потерь (другими словами, производную) для улучшения весов нейронной сети.
Чтобы понять основную концепцию процесса градиентного спуска, давайте рассмотрим базовый пример нейронной сети, состоящей только из одного входного и одного выходного нейрона, соединенных значением веса ш .
Эта нейронная сеть получает входные данные x и выдает прогноз y .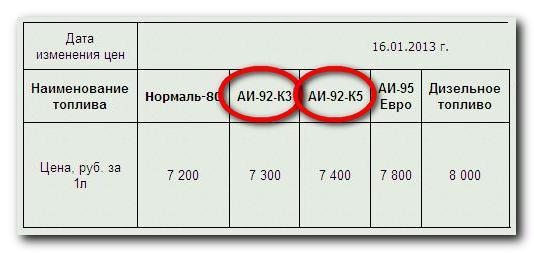 Допустим, начальное значение веса этой нейронной сети равно
Допустим, начальное значение веса этой нейронной сети равно 5 , а входное значение x равно 2 . Поэтому предсказание y этой сети имеет значение 10 , тогда как метка y_hat может иметь значение 6 .
Это означает, что прогноз неточен, и мы должны использовать метод градиентного спуска, чтобы найти новое значение веса, которое заставляет нейронную сеть делать правильный прогноз. На первом этапе мы должны выбрать функцию потерь для задачи.
Давайте возьмем квадратичные потери, которые я определил выше, и построим график этой функции, которая в основном представляет собой просто квадратичную функцию: и, следовательно, параметры сети — в данном случае один вес w . Ось x представляет значения для этого веса.
Как видите, существует определенный вес w , для которого функция потерь достигает глобального минимума. Это значение является оптимальным параметром веса, который заставит нейронную сеть сделать правильный прогноз (что составляет 6 ).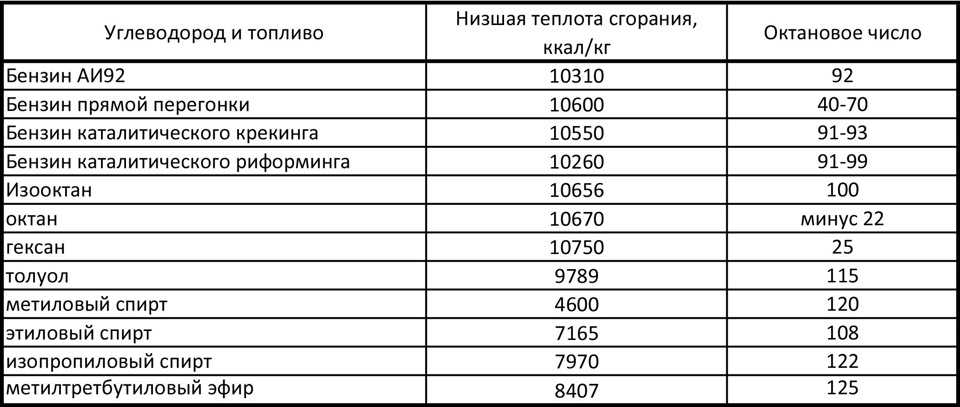 В этом случае значение оптимального веса равно
В этом случае значение оптимального веса равно 3 :
С другой стороны, наш начальный вес равен 5 , что приводит к довольно большим потерям. Теперь цель состоит в том, чтобы неоднократно обновлять параметр веса, пока мы не достигнем оптимального значения для этого конкретного веса. Это время, когда нам нужно использовать градиент функции потерь.
К счастью, в этом случае функция потерь является функцией одной единственной переменной, веса w :
На следующем шаге вычисляем производную функции потерь по этому параметру:
Градиент функции потерь В итоге получаем 8 , что дает нам значение наклон или тангенс функции потерь для соответствующей точки на оси x, в которой находится наш начальный вес.
Эта касательная указывает на максимальную скорость увеличения функции потерь и соответствующих весовых параметров на оси x.
Это означает, что мы только что использовали градиент функции потерь, чтобы выяснить, какие параметры веса приведут к еще большему значению потерь. На самом деле мы хотим знать прямо противоположное. Мы можем получить то, что хотим, если умножим градиент на
На самом деле мы хотим знать прямо противоположное. Мы можем получить то, что хотим, если умножим градиент на -1 и, таким образом, получим противоположное направление градиента.
Вот как мы получаем направление наибольшей скорости убывания функции потерь и соответствующие параметры на оси x, которые вызывают это уменьшение:
Наконец, мы выполняем один шаг градиентного спуска, пытаясь улучшить наши веса. Мы используем этот отрицательный градиент для обновления вашего текущего веса в направлении весов, для которых значение функции потерь уменьшается в соответствии с отрицательным градиентом: -параметр, называемый скоростью обучения. Скорость обучения определяет, насколько быстро или медленно вы хотите обновлять параметры.
Пожалуйста, имейте в виду, что скорость обучения — это коэффициент, на который мы должны умножить отрицательный градиент, и что скорость обучения обычно довольно мала. В нашем случае скорость обучения составляет 0,1 .
Как видите, наш вес w после градиентного спуска теперь равен 4.2 и ближе к оптимальному весу, чем был до шага градиента.
Значение функции потерь для нового значения веса также меньше, а это значит, что нейронная сеть теперь способна делать лучшие прогнозы. Вы можете произвести расчет в уме и увидеть, что новый прогноз на самом деле ближе к метке, чем раньше.
Каждый раз, когда мы обновляем веса, мы двигаемся вниз по отрицательному градиенту к оптимальным весам.
После каждого шага градиентного спуска или обновления веса текущие веса сети становятся все ближе и ближе к оптимальным весам, пока мы в конце концов не достигнем их. В этот момент нейронная сеть сможет делать прогнозы, которые мы хотим сделать.
Что такое искусственный интеллект (ИИ)?
Хотя за последние несколько десятилетий появилось несколько определений искусственного интеллекта (ИИ), Джон Маккарти предлагает следующее определение в этой статье 2004 г.
Однако за десятилетия до этого определения рождение разговора об искусственном интеллекте было обозначено основополагающей работой Алана Тьюринга «Вычислительные машины и интеллект» (PDF, 89,8 КБ) (ссылка находится за пределами IBM), которая была опубликована в 1950 году. В этой статье Тьюринг, которого часто называют «отцом информатики», задает следующий вопрос: «Могут ли машины думать?» Оттуда он предлагает тест, теперь известный как «Тест Тьюринга», в котором следователь-человек пытается различить текстовый ответ компьютера и человека. Хотя этот тест подвергся тщательному анализу с момента его публикации, он остается важной частью истории ИИ, а также постоянной концепцией в философии, поскольку он использует идеи, связанные с лингвистикой.
Затем Стюарт Рассел и Питер Норвиг опубликовали книгу «Искусственный интеллект: современный подход» (ссылка не принадлежит IBM), которая стала одним из ведущих учебников по изучению ИИ. В нем они углубляются в четыре потенциальных цели или определения ИИ, которые различают компьютерные системы на основе рациональности и мышления по сравнению с действиями:
Человеческий подход:
- Системы, мыслящие как люди
- Системы, которые действуют как люди
Идеальный подход:
- Системы, мыслящие рационально
- Рационально действующие системы
Определение Алана Тьюринга подпадало бы под категорию «систем, которые действуют как люди».
В своей простейшей форме искусственный интеллект — это область, которая сочетает в себе информатику и надежные наборы данных для решения проблем. Он также охватывает подобласти машинного обучения и глубокого обучения, которые часто упоминаются в связи с искусственным интеллектом.