Расшифровка аи бензин: на что влияют октановые числа бензина — Mafin Media
на что влияют октановые числа бензина — Mafin Media
Все
Новости
Разборы
Термины
Гайды
Инфографика
Тесты
Правильно подобранное топливо может продлить срок службы двигателя и сделать поездки комфортными и безопасными. Но неправильный выбор чреват серьезными проблемами. Чем отличаются разные виды бензина и как выбрать подходящий? Объясняем в новом разборе Mafin Media.
Что такое октановое число и почему это важный показатель
Сама аббревиатура АИ говорит о том, что это топливо для автомобилей. Буква «А» обозначает автотранспорт, а буква «И» — что октановое число этого топлива было проверено в лаборатории исследовательским методом. Цифры, которые стоят после обозначения типа топлива, и указывают на то самое число. Всего на российском рынке представлено четыре вида бензина: АИ-92, АИ-95, АИ-98 и АИ-100. Возможно, где-то в российских глубинках еще можно найти АИ-80, но на автозаправочных станциях Москвы и Санкт-Петербурга такого топлива уже точно нет: современные моторы просто на него не рассчитаны.
Октановое число говорит о стойкости бензина к детонации — процессу взрывного воспламенения рабочей смеси. В цилиндре двигателя внутреннего сгорания находится поршень, который ходит вверх-вниз. Когда он движется к нижней точке, в цилиндр подается топливо и воздух. После этого поршень движется вверх, сжимая топливно-воздушную смесь для ее дальнейшего воспламенения, а искра от автомобильной свечи поджигает сжатую смесь в камере сгорания. После этого поршень идет вниз, создавая инерцию для дальнейшего вращения двигателя. В следующем подъеме поршень выталкивает сгоревшие газы из камеры сгорания. Такт считается завершенным, и процесс повторяется снова.
Октановое число показывает, насколько сильно можно сжать топливно-воздушную смесь, прежде чем произойдет детонация. Если использовать топливо с октановым числом ниже рекомендованного заводом-изготовителем, может произойти ранний взрыв смеси еще в середине такта сжатия. В таком случае поршень встретит сопротивление от взрывной волны, прежде чем дойдет до верхней точки и завершит такт. Это чревато не только тем, что автомобиль начнет ехать хуже, но и ощутимым сокращением срока службы мотора — например, сам поршень со временем начнет разрушаться и плавиться от резких повышений температуры, шатуны (деталь соединяющая поршень и коленчатый вал двигателя) из-за перегрузки могут деформироваться. Одним словом, рано или поздно (скорее, рано) двигатель потребует замены или капремонта.
Это чревато не только тем, что автомобиль начнет ехать хуже, но и ощутимым сокращением срока службы мотора — например, сам поршень со временем начнет разрушаться и плавиться от резких повышений температуры, шатуны (деталь соединяющая поршень и коленчатый вал двигателя) из-за перегрузки могут деформироваться. Одним словом, рано или поздно (скорее, рано) двигатель потребует замены или капремонта.
#Авто
#Автоликбез
Подберите самые выгодные условия по КАСКО
Введите номер авто — данные заполнятся автоматически
или нажмите «Рассчитать», если еще не получили его
Анастасия Мельник
Автор
Mafin Team
Подписывайтесь на Telegram-канал Mafin Media и не упускайте новых знаний и возможностей!
Актуальное
16 сентября 2022
Нужно ли платить налог при продаже авто
15 сентября 2022
Нужна ли доверенность на управление авто в 2022 году
6 сентября 2022
Как рассчитывается капитальный ремонт и какие бывают льготы
2 сентября 2022
Шенгенская виза — 2022.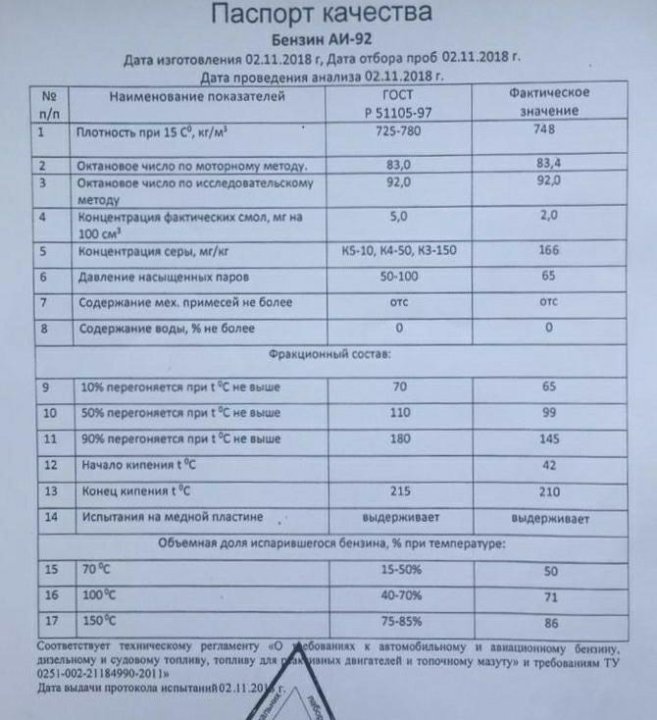 Как теперь получить и кто еще выдает
Как теперь получить и кто еще выдает
Что такое Mafin?Контакты
Наши партнерыМобильное приложение
Оставить отзывЮридические документы
Mafin Media
8 800 555 1 555
© 2022 Mafin — информационный сервис ООО «Эл Си Системс» (ОГРН 1157746012126, ИНН 7730004900, юр. адрес: 121248, г. Москва, Кутузовский проспект, дом 12, строение 6, этаж 1, помещение I, комната 23). Содействие в подборе страховых услуг и технологическая платформа предоставляются ООО «АбсолютТех» (ОГРН 1187746813528, ИНН 7725497400, г. Москва, улица Ленинская Слобода, дом 19, строение 6, 4 этаж, комната 76). Mafin использует файлы cookies с целью повышения удобства пользования сайтом. Подробнее об условиях использования
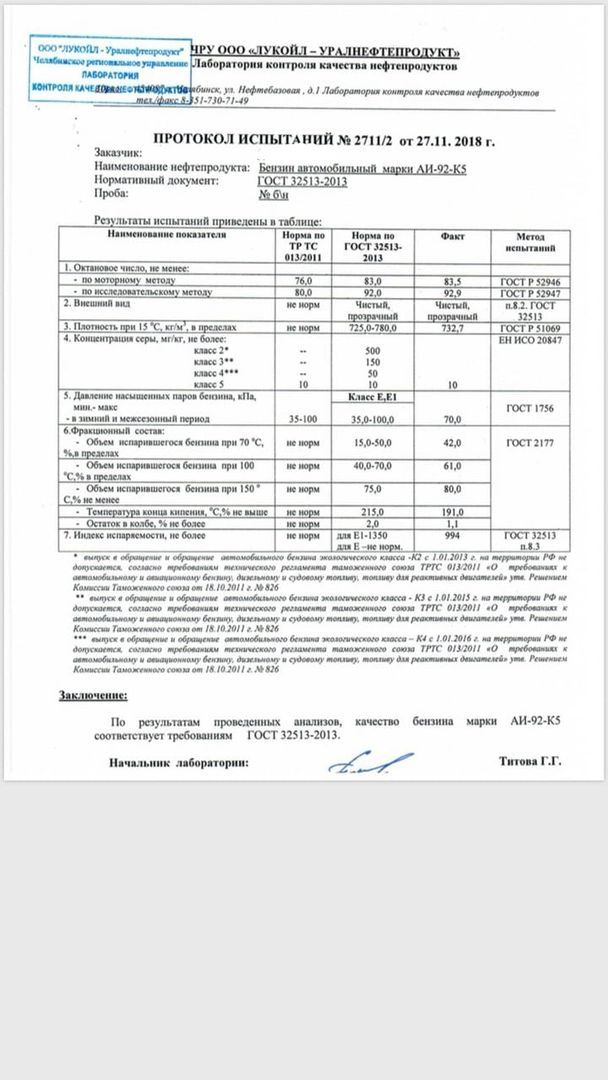
Бензин АИ-92 — характеристики, расшифровка, реализация
Home > О топливе > Бензин АИ-92
Posted on by oilselling-admin
Бензин АИ-92 – самое популярное в России топливо для карбюраторных и инжекторных моторов. На нем ездят почти все автомобили российского производства, а также большинство стареньких иномарок. Неэтилированный АИ-92 не содержит соединений тяжелых металлов, в том числе, свинца. АИ-92 хорошего качества позволяет автомобилю раскрыть 100% своего потенциала и не приводит к быстрому изнашиванию деталей мотора.
На нем ездят почти все автомобили российского производства, а также большинство стареньких иномарок. Неэтилированный АИ-92 не содержит соединений тяжелых металлов, в том числе, свинца. АИ-92 хорошего качества позволяет автомобилю раскрыть 100% своего потенциала и не приводит к быстрому изнашиванию деталей мотора.
Расшифровка АИ-92 означает, что это бензин автомобильный (буква А), октановое число которого (ОЧ 92) было рассчитано исследовательским методом (буква И) в условиях, максимально соответствующих стандартным городским.
Многие считают, что более высокая цифра октанового числа говорит о лучшем качестве топлива. Но это не так. Число здесь показывает только устойчивость топлива к детонации, не более. И выбирая, каким видом топлива заправить своего железного коня, нужно ориентироваться на рекомендации завода-изготовителя.
Характеристики
ГОСТ на АИ-92 предусматривает для этой марки бензина следующие свойства:
- Содержание свинца – не более 0,013
- Содержание смол – не более 5 мг/дм3 (промытых растворителем)
- Массовая доля серы – не более 0,05%
- Плотность (или удельный вес) – 725-780 кг/м3
Другие важные характеристики:
- Температура вспышки.
 Для бензинов она составляет в среднем -39 градусов. Это минимальный порог нагрева топлива, при котором легкие его фракции, отделяясь, могут вспыхнуть при приближении источника пламени.
Для бензинов она составляет в среднем -39 градусов. Это минимальный порог нагрева топлива, при котором легкие его фракции, отделяясь, могут вспыхнуть при приближении источника пламени. - Температура горения. Этот показатель отражает, какую максимальную температуру может создавать горящий бензин. Он достигает 1300-1400 градусов.
- Температура кипения. Показывает, какой должна быть температура окружающего воздуха, чтобы бензин в двигателе закипел. Раньше в летнюю жару «кипящий» мотор был нередким явлением. АИ-92 может закипеть при температуре от 33 до 205 градусов (в зависимости от производителя и состава).
- Цвет. Оттенок 92-го бензина должен быть естественным – от бесцветного до соломенно-желтого. При этом структура топлива должна быть однородной, чистой и прозрачной без взвесей.
 Для бензинов она составляет в среднем -39 градусов. Это минимальный порог нагрева топлива, при котором легкие его фракции, отделяясь, могут вспыхнуть при приближении источника пламени.
Для бензинов она составляет в среднем -39 градусов. Это минимальный порог нагрева топлива, при котором легкие его фракции, отделяясь, могут вспыхнуть при приближении источника пламени.Еще одно важнейшее свойство – фракционный состав бензина. Это показатель его испаряемости и того, как ведет себя топливо в разных фракциях: пусковой, рабочей и концевой. По ГОСТ фракционный состав измеряется на 5 стадиях: начало перегонки, перегонка 10% от объема, далее 50%, 90% и в конце кипения.
Экологический класс
Согласно ОКПД (общероссийскому классификатору продукции) бензином АИ-92 может называться бензин автомобильный с октановым числом выше 92 (но не выше 95) и соответствующий, как минимум, классу К2.
Экологические классы бензина (К2 – К5) предусматривают различное содержание серы в топливе. От 500 мг/кг для К2 до 10 мг/кг для К5. Чем меньше в составе бензина серы, а вместе с ней монометиланина, тем безопаснее для экологии данное топливо.
В маркировке бензина экологический класс указывается после октанового числа. Например, АИ-92-4.
Срок годности
В советское время считалось, что бензин не теряет своих свойств при хранении и его срок годности достигает 5 лет. Но это не так. При длительном хранении бензин начинает испаряться, окисляться, у него распадаются присадки, использованные для повышения октанового числа, и образуется осадок. Также могут расслаиваться фракции из-за разности плотности.
Поэтому сейчас максимальный срок хранения бензина не превышает 1 год с момента производства.
Реализация АИ-92
Многих интересует вопрос, что собой представляет тонна бензина АИ-92 в литрах? Если считать плотность 92-го равной 0,735 кг/л, то в тонне этой марки бензина будет 1360,5 литров.
Но главное, что волнует всех автолюбителей, это разница между АИ-92 и АИ-95. Есть ли она?
В сравнении с 92-м, АИ-95 позиционируется как бензин повышенного качества. Здесь больше добавок, снижающих взрывоопасность, и при производстве полностью исключен свинец. Плюс за счет добавления моющих присадок топливо обладает чистящими свойствами для мотора.
В целом, при использовании качественного топлива обоих видов, разница при обычной эксплуатации незаметна. На все же лучше ориентироваться на рекомендации производителя автомобиля.
Купить бензин оптом
Синтетическое топливо | Bosch Global
До недавнего времени углеродно-нейтральный двигатель внутреннего сгорания был предметом мечтаний. Теперь это может скоро стать реальностью. Секрет кроется в синтетических или углеродно-нейтральных видах топлива, в процессе производства которых улавливается CO₂, что вносит значительный вклад в сдерживание глобального потепления.
Для достижения климатических целей выбросы CO₂ от дорожного движения во всем мире должны быть сокращены на 50 процентов в течение следующих четырех десятилетий, а в странах с развитой экономикой — как минимум на 85 процентов.
В конце концов, даже если все автомобили когда-нибудь будут ездить на электричестве, самолеты, корабли и даже грузовики все равно будут работать в основном на топливе. Таким образом, углеродно-нейтральные двигатели внутреннего сгорания, работающие на синтетическом топливе, являются очень многообещающим направлением для изучения — в том числе и для легковых автомобилей.
2,8 гигатонны CO₂
можно было бы сэкономить к 2050 году за счет использования синтетического топлива.
Синтетические или углеродно-нейтральные виды топлива улавливают CO₂ в процессе производства. Таким образом, этот парниковый газ становится сырьем, из которого можно производить бензин, дизельное топливо и природный газ-заменитель с помощью электроэнергии из возобновляемых источников. Еще одним важным преимуществом двигателя внутреннего сгорания, использующего синтетическое топливо, является то, что существующая сеть заправочных станций может продолжать использоваться.
Еще одним важным преимуществом двигателя внутреннего сгорания, использующего синтетическое топливо, является то, что существующая сеть заправочных станций может продолжать использоваться.
То же самое относится к существующей экспертизе двигателей внутреннего сгорания. Более того, даже несмотря на то, что электромобили станут значительно дешевле в ближайшие годы, разработка этих видов топлива может быть полезной. Bosch подсчитал, что при пробеге в 160 000 километров общая стоимость владения гибридом, работающим на синтетическом топливе, может быть меньше, чем у электромобиля для дальних поездок, в зависимости от типа используемой возобновляемой энергии.
Что должно произойти, прежде чем синтетическое топливо станет общепринятым?
Несмотря ни на что, необходимы значительные усилия, прежде чем синтетические виды топлива смогут стать общепризнанными. Перерабатывающие мощности по-прежнему дороги, а опытных заводов всего несколько. Таким образом, Министерство экономики и энергетики Германии поддерживает синтетическое топливо в рамках своей инициативы «Альтернативные источники энергии на транспорте». Широкому использованию этих видов топлива также будет способствовать увеличение доступности и, следовательно, снижение цен на электроэнергию из возобновляемых источников энергии.
Перерабатывающие мощности по-прежнему дороги, а опытных заводов всего несколько. Таким образом, Министерство экономики и энергетики Германии поддерживает синтетическое топливо в рамках своей инициативы «Альтернативные источники энергии на транспорте». Широкому использованию этих видов топлива также будет способствовать увеличение доступности и, следовательно, снижение цен на электроэнергию из возобновляемых источников энергии.
Как производится синтетическое топливо?
Синтетическое топливо производится исключительно с помощью возобновляемых источников энергии. На первом этапе водород получают из воды. К этому добавляется углерод для получения жидкого топлива. Этот углерод можно перерабатывать в промышленных процессах или даже улавливать из воздуха с помощью фильтров. Сочетание CO₂ и H₂ дает синтетическое топливо, которое может быть бензином, дизельным топливом, газом или даже керосином.
Насколько дорогим будет новое топливо?
В настоящее время производство синтетического топлива является сложным и дорогостоящим процессом. Однако увеличение производства и благоприятные цены на электроэнергию могут означать, что синтетическое топливо станет значительно дешевле. Нынешние исследования показывают, что само топливо (без учета акцизных сборов) в долгосрочной перспективе может стоить от 1,00 до 1,40 евро за литр.
В чем разница между синтетическим топливом и биотопливом?
Синтетическое топливо не означает выбора между топливным баком и обеденной тарелкой, в отличие от биотоплива. А если используются возобновляемые источники энергии, синтетическое топливо можно производить без ограничений по объему, которые можно ожидать в случае биотоплива из-за таких факторов, как количество доступной земли.
Резюме
Синтетическое топливо может сделать автомобили с бензиновыми и дизельными двигателями углеродно-нейтральными и, таким образом, внести значительный вклад в ограничение глобального потепления.
Мобильность Electrified Mobility Research
StoryElectrified Mobility
Вождение на электричестве!
StoryMobility
Будущее городской мобильности
Стратегии упрощенного декодирования для повышения специфичности
1 Введение
Известно, что языковые модели (LM) производят расплывчатые и общие результаты (Holtzman et al., 2019) . В таких областях, как обобщение Fan et al. (2018) , создание диалогов Yao et al. (2016) и креативные вычисления Fan et al. (2018)
,
часто желательны результаты с более высокой специфичностью. При контроле специфичности
выходных данных модели изучались ранее, в первую очередь
рассматривается как контролируемая задача обучения, когда доступ к большим внутридоменным
тренировочные наборы являются предпосылками для реализации.
При контроле специфичности
выходных данных модели изучались ранее, в первую очередь
рассматривается как контролируемая задача обучения, когда доступ к большим внутридоменным
тренировочные наборы являются предпосылками для реализации.
Однако, предварительно обученные LM становятся все более качественными так что для получения требуется только текстовая подсказка генератор языка для конкретных задач Brown et al. (2020) . Было бы полезно контролировать специфичность выходных данных этих моделей неконтролируемым образом. потому что переобучение или тонкая настройка таких моделей являются нетривиальными или невыполнимыми задачами — например, потому что языковая модель слишком велика и доступна только через API, или задача генерации не имеет обучающих данных.
С этой целью мы предлагаем две стратегии неконтролируемого декодирования для повышения специфичности LM, которые могут работать с любым LM, который выводит распределение вероятностей по своему словарю во время генерации. Первый основан на частоте слов, а второй — на положительной точечной взаимной информации (PPMI). Мы показываем в задаче быстрого завершения, что неконтролируемые стратегии повторного взвешивания, основанные на этих количествах
улучшает специфичность генерируемых выходных данных, лишь незначительно влияя на чувствительность, по мнению комментаторов-людей.
Первый основан на частоте слов, а второй — на положительной точечной взаимной информации (PPMI). Мы показываем в задаче быстрого завершения, что неконтролируемые стратегии повторного взвешивания, основанные на этих количествах
улучшает специфичность генерируемых выходных данных, лишь незначительно влияя на чувствительность, по мнению комментаторов-людей.
Этот документ состоит из четырех основных дополнений: 1 1 1 Реализации и оценки будут опубликованы после анонимного просмотра.
Мы предлагаем схемы повторного взвешивания на основе частоты слов и PPMI распределения вероятностей вывода LM для повышения специфичности.
Мы проверяем с помощью человеческих оценок задачи быстрого завершения, что эти схемы улучшают специфичность лишь с небольшим снижением до чувствительность. Мы находим, что это справедливо как в детерминированном и стохастические настройки генерации.
Мы проверяем с помощью автоматических мер, что эти схемы улучшают разнообразие выходов в детерминированных настройках генерации.
Мы показываем, как эти схемы можно использовать для управления генерируемыми сводками новостных статей.

2 Связанная работа
Частота слов и PPMI использовались в предыдущей работе для контроля специфичность получаемых результатов. Яо и др. (2016)
обучить модель генерации диалогов с помощью контролируемая цель обучения и обучение с подкреплением, чтобы максимизировать обратный документ частота (IDF) генерируемых ответов, что повышает качество как генерации, так и поиска. Соответственно,
Ко и др. (2019) обусловливают декодер различными показателями (включая частоту слов), чтобы повысить специфичность при создании диалогов, и обнаружить, что лингвистически обусловленные показатели генерируют наиболее информативные и актуальные ответы. Чжан и др. (2018) обучают модель генерации нейронных диалогов, которая принимает в качестве входных данных текст предыдущего высказывания, а также нормализованную максимальную обратную частоту слов желаемого ответа, что значительно превосходит современные модели.
Хотя все четыре работы пытаются повысить специфичность генерируемых выходных данных, они делают это посредством обучения генератор языков с нуля. Кроме того, в то время как Yao et al. (2016)
добавляет только функцию потерь,
Ko et al. (2019) , Zhang et al. (2018) и Такаяма и Арасе (2020) добавить в декодер специально созданные нейронные компоненты
включить средства контроля специфичности, что было бы трудно
делать с большим, предварительно обученным LM, таким как GPT-3. По сравнению,
предлагаемые нами неконтролируемые повторные взвешивания не требуют переобучения, тонкой настройки или дополнительных
модификаций декодера и может работать с любым LM, производящим
распределение вероятностей
над следующими токенами.
3 Управление специфичностью поколения
Мы представляем два способа изменить распределение вероятностей LM. Первый опирается на нормализованные обратные частоты слов (NIWF), которые могут быть легко рассчитаны с использованием любого желаемого корпуса и не зависят от подсказки. Второй основан на вычислении положительной точечной взаимной информации (PPMI), которая может быть рассчитана с использованием любого желаемого корпуса, но зависит от определения некоторого контекста (вероятно, слова или слов из подсказки) для вычисления.
В любом случае корпус (который не обязательно должен быть исходным обучающим корпусом) используется для изменения распределения вероятности, выходящего из LM.
Обе схемы модифицируют исходный дистрибутив, добавляя специфический для токена термин bt∈R. к ненормированной логарифмической вероятности ati∈R:
к ненормированной логарифмической вероятности ati∈R:
| (оригинальная модель) | logpθ(ти) | ∝ати | (1) | ||
| (перевзвешенная модель) | logpθ(ti) | ∝ати+бт | (2) |
где pθ(ti) — вероятность LM создания токена т на шаге I. 2 2 2 Обычно pθ(ti) зависит от ранее сгенерированные токены t1,…,ti−1 и, возможно, контекст c, но мы опускаем здесь их явное указание, так как они не нужны для объяснения схем повторного взвешивания.
3.1 Нормализованная обратная частота слов (NIWF)
NIWF часто используется для измерения специфичности (Ли и Ненкова, 2015; Ко и др., 2019) ; здесь мы используем его для расчета модифицированной вероятности для каждого токена ti в модели (во время генерации).
Пусть nt будет количеством токенов t в корпусе и пусть
n∗=maxt∈Vnt — максимальное количество
происходит в корпусе. Затем повторное взвешивание NIWF токена t рассчитывается как:
Затем повторное взвешивание NIWF токена t рассчитывается как:
| бт=мин(макс(w0,n∗knt),w1) | (3) |
, где k∈R — скаляр для настройки диапазона, а w0,w1∈R — нижняя и верхняя границы соответственно. Мы устанавливаем k=100. На практике n∗knt может варьироваться в широких пределах. Чтобы гарантировать, что распределение вероятностей модели не будет нарушено до неузнаваемости, мы устанавливаем w0=exp(−5) и w1=1, чтобы ограничить bt примерно между 0 и 1. Эффект состоит в том, что самые редкие слова получают увеличение не более чем на 1 к оригиналу ати срок при этом общеупотребительные слова почти не получат прибавки.
3.2 Положительная точечная взаимная информация (PPMI)
PPMI — еще одна мера, часто связанная со специфичностью термина Takayama and Arase (2020) и измеряющая положительную связь между двумя событиями.
Это повторное взвешивание требует события контекста, между которым вычисляется PPMI
токены из модельного словаря. В нашем случае пусть контекст c⊂V будет набором тематически связанных слов из текста подсказки, мы хотели бы, чтобы LM
для завершения (конкретный пример см. в разделе 4.1).
В нашем случае пусть контекст c⊂V будет набором тематически связанных слов из текста подсказки, мы хотели бы, чтобы LM
для завершения (конкретный пример см. в разделе 4.1).
Затем мы определяем термин модификации bt как
| бт=макс(0,logp(c,t)p(c)p(t)) | (4) |
, где p(c), p(t) и p(c,t) предельная вероятность появления контекстных слов c, предельная вероятность появления токена t, а совместная вероятность контекстных слов c и токен t совпадают соответственно.
Эти вероятности оцениваются из корпуса предложений с
p(c,t)=nc,tns, p(c)=ncns и р (т) = нтнс где nt — количество предложений, в которых встречается токен t, nc — количество предложений, в которых встречаются контекстные слова c, nc,t — количество предложений, в которых и контекстное слово, и t происходят одновременно, и ns — размер корпуса в предложениях.
Приложение А показывает
как эти повторные взвешивания влияют на вероятности журнала для конкретной подсказки.
4 Эксперимент
Чтобы проверить эти методы, мы используем задание на научное письмо, в котором модель должна создать именное словосочетание по технической теме. Например, одна подсказка — «Кто использует криптографию». Это задание требует, чтобы LM сказал что-то разумное, имеющее смысл в данной теме, и конкретное, что не относится к любой теме. Это сложная задача для большинства предварительно обученных LM, которые, как правило, выдают очень расплывчатые результаты (например, заполнение подсказки криптографии с помощью «людей» или «многих»).
Мы используем пять тем, выбранных случайным образом из списка тем Википедии по компьютерным наукам: 3 3 3 взаимодействие человека с компьютером, машины опорных векторов, базы данных, а также структуры данных.
Для каждой темы мы используем четыре подсказки для создания словосочетаний с существительными: «используется», «используется в», «изучается» и «изучается в». о теме. Для каждой подсказки мы генерируем пять выходных словосочетаний с существительными. Эта настройка приводит к 100 утверждениям для каждого условия (5 тем × 4 подсказки × 5 выводов), которые можно оценить по тому, насколько разумным и конкретным является утверждение.
о теме. Для каждой подсказки мы генерируем пять выходных словосочетаний с существительными. Эта настройка приводит к 100 утверждениям для каждого условия (5 тем × 4 подсказки × 5 выводов), которые можно оценить по тому, насколько разумным и конкретным является утверждение.
Мы рассматриваем две парадигмы генерации: детерминированную (поиск луча) и стохастическую (выборка по k). Для каждой парадигмы у нас есть три условия: исходная модель (без повторного взвешивания), повторное взвешивание NIWF и повторное взвешивание PPMI. Кроме того, для выборки top-k мы также запускаем исходную модель с параметром температуры, установленным на τ = 1,7 (выбранным таким образом, чтобы среднее недоумение выходных данных на слово соответствовало значениям из схемы повторного взвешивания NIWF). В таблице 1 показаны примеры выходных данных для каждого условия.
4.1 Детали реализации
Мы используем реализацию GPT-2 Hugging Face (gpt2-large) 4 4 4https://huggingface. co/gpt2-large в качестве нашего предварительно обученного LM. Для расчета повторного взвешивания мы используем свод новостных статей Vox, 5 5 5https://data.world/elenadata/vox-articles, который содержит более 30 миллионов токенов.
co/gpt2-large в качестве нашего предварительно обученного LM. Для расчета повторного взвешивания мы используем свод новостных статей Vox, 5 5 5https://data.world/elenadata/vox-articles, который содержит более 30 миллионов токенов.
Для повторного взвешивания PPMI мы рассматриваем контекст c как маркеры, составляющие название темы информатики. 6 6 6 Чтобы уменьшить разреженность подсчетов совпадений на уровне предложений, для каждой темы контекст c мы также вручную добавляем морфологически родственные слова (например, c={cryptography,cryptographic,cryptographer,…}). Для топ-k выборки (Fan et al., 2018) мы установили k=50. Чтобы выходные данные для каждого приглашения были уникальными, мы задаем уникальность первому токену. Для каждой подсказки мы генерируем следующие 10 токенов и используем синтаксический анализатор для выбора первой именной фразы. Подробную информацию о выборе словосочетаний см. в Приложении B.
Базовая генерация: Colonial Pipeline перезапущен после шестидневного простоя. Операторы газопровода предупредили, что для восстановления нормального режима работы потребуется несколько дней. Закрытие вызвало панические покупки и накопления, которые захлестнули заправочные станции на юго-востоке. Операторы газопровода предупредили, что для восстановления нормального режима работы потребуется несколько дней. Закрытие вызвало панические покупки и накопления, которые захлестнули заправочные станции на юго-востоке. |
| NIWF + рынок (экономика): Colonial Pipeline перезапущен после шестидневного простоя. Трубопровод был закрыт после атаки программы-вымогателя. Он обеспечивает почти половину бензина и дизельного топлива, потребляемых Восточным побережьем. Руководители нефтяной отрасли предупредили в среду, что накопление газа усугубляет кризис поставок. |
| Атака PPMI + программы-вымогателя: Colonial Pipeline возобновил свою работу в среду вечером. Конвейер отключился в пятницу после атаки программы-вымогателя. Закрытие вызвало панические покупки и накопления, которые захлестнули заправочные станции на юго-востоке. |
 Курсивом выделены фразы, относящиеся к выбранной теме.
Курсивом выделены фразы, относящиеся к выбранной теме.4.2 Методология оценки
У нас есть два комментатора-человека, которые оценивают каждое утверждение на предмет того, насколько оно осмысленно и конкретно. Мы продолжаем предыдущую работу по получению суждений о чувствительности из LM-завершений Li et al. (2016) используя шкалу чувствительности от 0 до 4, где 0 — «не имеет смысла», а 4 — «в целом верно». Мы используем аналогичную шкалу от 0 до 4 для специфичности, где 0 — «Не уверен, применимо ли это», а 4 — «Относится к этой теме в частности». Мы рассчитываем взвешенный коэффициент Коэна, чтобы обеспечить адекватную надежность интераннотаций, и усредняем оценки аннотаторов, если они различаются. Каждый комментатор является аспирантом в области компьютерных наук, обладающим экспертными знаниями по темам. Для чувствительности у нас было κ = 0,35 (удовлетворительное согласие), а для специфичности у нас было κ = 0,53 (хорошее согласие).
Мы также рассчитываем три меры разнообразия
после Такаяма и Арасэ (2020) ..jpg) Мы сообщаем dist-1 и dist-2 (уникальность униграмм и биграмм) и ent-2 (энтропия на основе биграмм). Подробнее о мерах разнообразия см. в Приложении C.
Мы сообщаем dist-1 и dist-2 (уникальность униграмм и биграмм) и ent-2 (энтропия на основе биграмм). Подробнее о мерах разнообразия см. в Приложении C.
| схема | чувств | спецификация | расст1/расст2/энтер2 |
| поиск луча | |||
| оригинал | 3,67 | 1,27 | 0,32/0,54/4,17 |
| НВФ | 3,13* | 2,25* | 0,55/0,80/4,69 |
| ППМИ | 3,40* | 2,39* | 0,37/0,67/4,25 |
| Топ-k выборка (k=50) | |||
| оригинал | 3,19 | 1,50 | 0,58/0,95/5,17 |
| τ=1,7 | 3,12 | 1,51 | 0,67/0,98/5,26 |
| НИВФ | 3,35 | 2,27* | 0,70 / 0,97 / 4,98 |
| ППМИ | 3,26 | 2,27* | 0,52/0,87/4,54 |
 Лучший (наибольший) результат выделен жирным шрифтом. Для чувств и характеристик * отмечает значительное отличие от оригинала.
Лучший (наибольший) результат выделен жирным шрифтом. Для чувств и характеристик * отмечает значительное отличие от оригинала.4.3 Результаты
Результаты для всех показателей можно увидеть в таблице 3. Мы проводим тесты значимости (ранговый критерий Манна-Уитни для непараметрических данных) для всех условий по сравнению с исходной моделью и сообщаем о значимых результатах при p<0,001. Мы обнаружили, что повторное взвешивание значительно увеличивает показатели специфичности: в детерминированном случае NIWF увеличил абсолютную специфичность на 0,9.8 и ППМИ на 1,12; в стохастическом случае NIWF увеличил абсолютную специфичность на 0,77, а PPMI на 0,77. Повышение температуры распределения практически не увеличивало специфичность — всего на 0,01 (незначительно).
Кроме того, в стохастической настройке мы находим
что это увеличение специфичности фактически немного увеличивает чувствительность. Небольшое снижение энтропии биграмм (ent2) для стохастических NIWF и PPMI также предполагает, что распределение выборки больше ориентировано на тематические слова, чем стандартные модели или модели с повышенной температурой.
В детерминистских условиях мы наблюдали умеренное, но значительное снижение чувствительности в детерминистической парадигме — NIWF снизил чувствительность на 0,54, а PPMI на 0,27, компромисс, обнаруженный в предыдущей работе (Ko et al., 2019) . В то же время автоматические метрики предполагают, что повторные взвешивания, особенно PPMI, улучшают разнесение при поиске луча, что желательно во многих задачах (Li et al., 2016) .
5 Вариант использования: обобщение
Чтобы оценить обобщаемость наших переоценок специфичности, мы применяем их к суммированию. В таблице 2 мы сравниваем обобщение исходного уровня с созданием сводок с повторным взвешиванием специфичности.
Чтобы вычислить сводки, мы используем реализацию Hugging Face (пегаса), точно настроенную на наборе данных CNN Dailymail. 7 7 7https://huggingface.co/google/pegasus-cnn_dailymail
Каждое резюме создается из одной и той же статьи о кибератаке Colonial Pipeline. 8 8 8https://www.cnn.com/2021/05/12/business/colonial-pipeline-restart/index.html
Чтобы рассчитать повторное взвешивание NIWF, мы вычисляем количество слов на странице Википедии «Рынок (экономика)». Чтобы рассчитать повторное взвешивание PPMI, мы используем «атаку программ-вымогателей» в качестве нашего контекста и используем новостную статью, чтобы получить количество совпадений слов и контекста. И корпус NIWF, и контекст PPMI выбираются пользователем вручную.
8 8 8https://www.cnn.com/2021/05/12/business/colonial-pipeline-restart/index.html
Чтобы рассчитать повторное взвешивание NIWF, мы вычисляем количество слов на странице Википедии «Рынок (экономика)». Чтобы рассчитать повторное взвешивание PPMI, мы используем «атаку программ-вымогателей» в качестве нашего контекста и используем новостную статью, чтобы получить количество совпадений слов и контекста. И корпус NIWF, и контекст PPMI выбираются пользователем вручную.
Благодаря повторному взвешиванию специфики сводка больше фокусируется на выбранной теме. По сравнению со стандартным резюме, резюме NIWF включает больше предложений, относящихся к «рынку», включая такие фразы, как «кризис предложения», «накопление газа» и «руководители нефтяной отрасли». Точно так же сводка PPMI включает конкретное предложение об атаке программы-вымогателя. Благодаря повторному взвешиванию пользователи могут определить контекст для создания сводок по интересующей их теме.
6 Заключение
Мы обнаружили, что частотность слов и схемы повторного взвешивания на основе PPMI повышают специфичность языковой модели с незначительным снижением чувствительности или его отсутствием.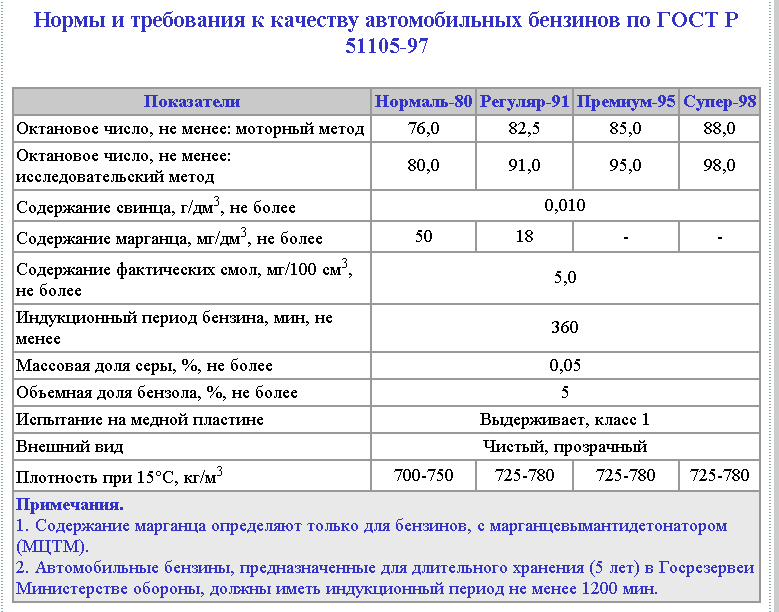 Мы демонстрируем, как эти схемы можно использовать для управления выходными данными языковой модели в других задачах, таких как суммирование.
Мы демонстрируем, как эти схемы можно использовать для управления выходными данными языковой модели в других задачах, таких как суммирование.
7 Заявление о более широком воздействии
В этой работе мы стремимся улучшить специфичность выходных данных языковой модели, вводя облегченные стратегии декодирования. Эта работа имеет как положительные, так и отрицательные последствия. Положительные результаты включают в себя повышение доступности управления большими предварительно обученными языковыми моделями для исследователей и практиков, а также снижение вычислительных затрат (и, следовательно, экологических и финансовых затрат) на управление большими предварительно обученными языковыми моделями.
Тем не менее, использование больших, предварительно обученных языковых моделей было поставлено под сомнение, учитывая гигантские объемы данных, на которых они обучаются, что усиливает гегемонистскую социальную перспективу и может нанести вред последующим задачам Bender et al. (2021) . Упрощение управления и использования этих моделей может побудить людей пренебрегать опасностями, связанными с этими моделями.
(2021) . Упрощение управления и использования этих моделей может побудить людей пренебрегать опасностями, связанными с этими моделями.
Ссылки
Приложение A Пример модифицированных вероятностей
Ниже приведен рисунок, показывающий, как наши схемы повторного взвешивания корректируют логарифмическую вероятность для конкретной подсказки.
Рисунок 1: NIWF и PPMI придают большее значение более конкретным словам, таким как «Биткойн» и «программное обеспечение».Приложение B Выбор первой фразы существительного
Для эксперимента, который представляет собой задачу завершения подсказки, мы создаем 10 токенов, а затем анализируем весь вывод (т. е. подсказку и сгенерированный текст) с помощью Spacy. 9 9 9https://spacy.io/ Чтобы выбрать первое именное словосочетание, мы выбираем либо первый кусок существительного, помеченный Spacy, либо поддерево первого существительного после третьего сгенерированного слова, в зависимости от того, что длиннее.