Расшифровка бензин аи: на что влияют октановые числа бензина — Mafin Media
Виды бензина, маркировка и расшифровка АИ в топливе
Что такое бензин? Как написано в Wikipedia, бензин — легковоспламеняющаяся жидкость на основе смеси легких углеводородов плотностью 0,71–0,77 г/см2. Температура ее замерзания –60 0С, кипения — в пределах 33–205 0С. Основная область применения — моторное топливо разных марок, сырье для органического синтеза, изготовления этилена и парафина. На ее основе производят: краски, лаки, растворители, мастики, другие вещества.
Основные характеристики
Какие бензины есть? В России производится несколько видов бензинов, отличающихся характеристиками и составом. Ключевым параметром для определения типов бензина является октановое число — ОЧ. Немаловажная роль при этом отводится количеству примесей. Основным составляющими горючей жидкости являются изооктан с гептаном, от которых зависит способность к детонации топлива в закрытом объеме. Их соотношение в готовом продукте определяет октановое число конкретного вида бензина.
Разновидности
Какой бензин есть в РФ и странах ТС? С учетом октанового числа и других характеристик, предусмотрены такие виды бензина в России:
- Автомобильное горючее изготавливается согласно ГОСТ 32513-2013: бензин-80, -92, -95, -98, -100, -101 и -102. Для справки — в СССР производился бензин-56, -66, -72, -74, -76 и -93.
| Характеристики автомобильных бензинов | ||||
| параметры | А-72 | А-92 | А-93 | А-95 |
| Минимальное ОЧ, моторный метод | 72 | 82,5 | 85 | 85 |
| Доля свинца, г/дм3 | до 0,13 | до 0,13 | до 0,13 | до 0,13 |
| Температура начала перегонки, 0С | от+35 | от+35 | от+35 | от +30 |
| Конец кипения, 0С | до +195 | до + 205 | до + 205 | до + 205 |
- Авиационное топливо изготавливается согласно ГОСТ 1012-2013: бензин-92 (Б-92) или бензин-91/115 (Б-91/115).
 По сравнению с автомобильным горючим оно отличается высоким ОЧ, хорошей стабильностью химической структуры и лучшими характеристиками. В таком топливе минимум примесей. В первую очередь, это касается легких фракций, формирующих паровые пробки, повышающих коррозию, образование нагара.
По сравнению с автомобильным горючим оно отличается высоким ОЧ, хорошей стабильностью химической структуры и лучшими характеристиками. В таком топливе минимум примесей. В первую очередь, это касается легких фракций, формирующих паровые пробки, повышающих коррозию, образование нагара. - Растворители применяются для химической отрасли. С их помощью осуществляется экстрагирование — извлечение нужных компонентов из растительного масла, озокерита или канифоли. В быту растворители используются для удаления разных пятен, разведения лака, краски, обезжиривания, других нужд.
- Лигроин (нафта). Фракции нефти на основе нормальных парафинов с температурой кипения до +180 0С. Основная сфера применения — сырье для производства этилена путем пиролиза.
 По сравнению с автомобильным горючим оно отличается высоким ОЧ, хорошей стабильностью химической структуры и лучшими характеристиками. В таком топливе минимум примесей. В первую очередь, это касается легких фракций, формирующих паровые пробки, повышающих коррозию, образование нагара.
По сравнению с автомобильным горючим оно отличается высоким ОЧ, хорошей стабильностью химической структуры и лучшими характеристиками. В таком топливе минимум примесей. В первую очередь, это касается легких фракций, формирующих паровые пробки, повышающих коррозию, образование нагара.
Как выглядит бензин?
Бензин — это газ или жидкость? В обычном состоянии — это жидкость с характерным запахом. Для удобства различия, еще с советских времен принято при производстве топлива добавлять особые красители. Схема оттенков видов бензина выглядит так:
Схема оттенков видов бензина выглядит так:
- АИ-66 имел зеленый цвет;
- АИ-72 отличался розовым тоном;
- АИ-76 изготавливали насыщенно-желтым;
- АИ-80 поставляется на АЗС желтого цвета;
- АИ-90 и АИ-95 различают по оранжево-красному оттенку;
- АИ- 98 производится с добавлением синего красителя.
Маркировка бензина и что обозначают цифры
Согласно ГОСТ 54283-2010 и нормам технического регламента от 2011 года на территории РФ предусмотрена маркировка бензинов в виде двух буквенных символов и двух цифр. Дополнительно иногда указывается еще одна цифра. Рассмотрим, как в бензине расшифровывается аббревиатура АИ и другие символы на таком примере: АИ-92/4.
- А — вид: автомобильное топливо;
- И — способ определения октанового числа: исследовательский. Если буква «И» отсутствует, значит, применялся моторный метод.
- 92 — величина октанового числа топлива;
- 4 — класс экологичности горючего может быть в диапазоне 2–5.

Методы определения ОЧ топлива
Основной характеристикой топлива является октановое число, определяющее детонационную стойкость горючей смеси. Чем выше этот параметр, тем позже (при большем давлении) происходит химическая реакция — воспламенение вещества с освобождением энергии и распространением ударной волны. В качестве эталонов используются два углеводорода:
- Изооктан имеет октановое число, равное единице или 100%. Другими словами, он не самовоспламеняется независимо от степени сжатия.
- Н-гептан отличается ОЧ, равным нулю. Следовательно, он быстро самовоспламеняется при малейшем давлении.
Если в топливе доля изооктана равна 95%, а н-гептана — 5%, значит, октановая характеристика такого горючего равна 95. Октановое число топлива измеряется в условных единицах и чаще всего в технических документах указывается, как ОЧ (ОЧМ, ОЧИ).
На практике существует две технологии определения ОЧ с помощью одноцилиндрового двигателя двухтактного типа:
- Исследовательская. Это способ предполагает имитацию движения автомобиля на крейсерском режиме с нагрузками не выше средних, когда обороты коленвала равны 600 об/мин.
- Моторная. При таком способе имитируются максимальные нагрузки с оборотами 900 об/мин.
 Это способ предполагает имитацию движения автомобиля на крейсерском режиме с нагрузками не выше средних, когда обороты коленвала равны 600 об/мин.
Это способ предполагает имитацию движения автомобиля на крейсерском режиме с нагрузками не выше средних, когда обороты коленвала равны 600 об/мин.Основным методом для определения октанового числа топлива является исследовательский способ.
Детонационная стойкость топлива
Детонация — химическая реакция с воспламенением топлива, при которой выделяется определенное количество тепловой энергии вместе с ударной волной. Фактически, это мгновенный взрыв горючего в замкнутом пространстве (камере сгорания), превращающий смесь в газообразные продукты горения, которые совершают механическую работу, обеспечивая движение поршня вниз. Благодаря этому происходит вращение коленчатого вала двигателя.
Все модификации бензиновых моторов, проектируются для использования топлива с конкретным октановым числом. Использование нештатного горючего приводит к преждевременному либо позднему воспламенению, в результате которого образуются детонационные волны.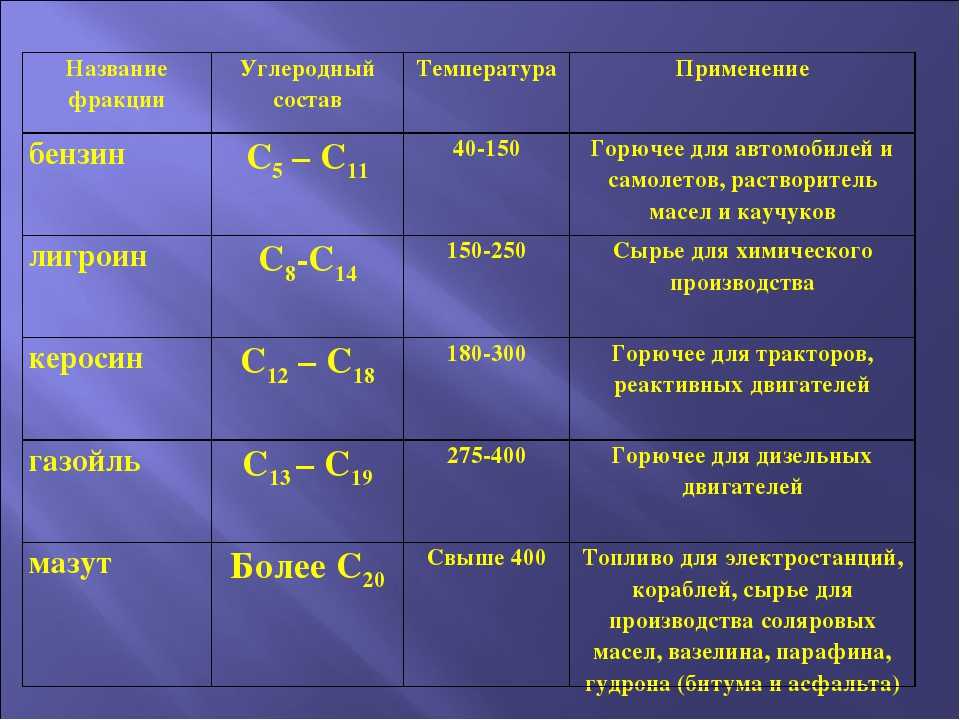 Они пагубно воздействуют на элементы конструкции, провоцируя их разрушение и последующий выход из строя мотора.
Они пагубно воздействуют на элементы конструкции, провоцируя их разрушение и последующий выход из строя мотора.
основные характеристики бензина – petrolcards.ru
Бензином регулярно пользуется практически каждый автовладелец. Нефтеперерабатывающие компании и АЗС по всей стране предлагают большое разнообразие горючего. Оно различается составом, наличием присадок, физическими и химическими свойствами, маркировкой.
Несложно заметить, что использование бензина разных марок обычно сразу же сказывается на работе двигателя и общих ходовых характеристиках авто. Но от правильного выбора топлива зависит не только скорость, но также надежность, безопасность и долговечность топливной и иных систем.
Какие параметры следует учитывать и на что обратить внимание владельцам автомобилей с бензиновыми двигателями?
Виды и типы бензинов
На отечественных заправках представлен бензин разного типа. Топливо различается составом, чистотой и некоторыми другими параметрами. Все они обычно маркируются с учетом их основного показателя – октанового числа.
Все они обычно маркируются с учетом их основного показателя – октанового числа.
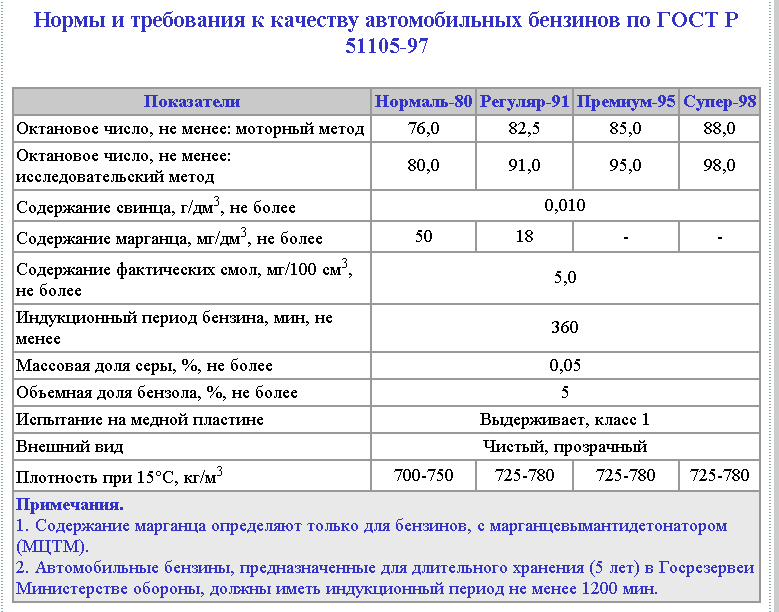
Требованиями ГОСТ, ТУ и других нормативных документов в РФ предусмотрены следующие марки бензинов: А-72, А-76, А-80, АИ-91, А-92, АИ-93, АИ-95, А-96, АИ-98. Потребление низкооктанового топлива в последнее время существенно снижается, высокооктанового, наоборот, растет. Бензин А-72 сегодня практически не используется, так как просто нет техники, которая бы на нем работала.
Более современная классификация бензинов насчитывает шесть основных видов этого топлива с различным октановым показателем:
- Нормаль – АИ-80.
- Регуляр – АИ-92.
- Премиум – АИ-95.
- Супер – АИ-95+.
- Экстра – АИ-98.
- ЭКТО – АИ-100.
Раньше в некоторые марки бензина для увеличения октанового числа добавлялись этиловые соединения, что позволяло повысить физико-химические свойства топлива с минимальным ростом его стоимости. Сегодня официально производство этилированного топлива прекращено.
Также современная маркировка предполагает указание не только отечественных, но и европейских стандартов: Евро-4, Евро-5 и т.д. Поэтому полное наименование бензина обычно выглядит следующим образом «АИ-98-5». Это означает, что бензин автомобильный (А), его октановое число определено по исследовательскому методу (И) и составляет 98, а по экологическим стандартам топливо соответствует техническим регламентам «Евро-5».
Октановое число бензина
Если говорить про основные параметры топлива, то его октановый показатель – едва ли не самая важная характеристика. При работе двигателя внутреннего сгорания топливная смесь сжимается под высоким давлением и потом воспламеняется. Происходит ее расширение. Для безопасности, надежности работы, сохранности двигателя и его отдельных элементов – важно, чтобы сгорание бензина происходило в нормальном режиме – без детонации. Октановое число как раз определяет детонационную стойкость топлива, что особенно важно в бензиновых двигателях с высокой степенью сжатия. Чем более качественный бензин, тем выше его октановое число. Кроме того, этот параметр сказывается и на расходе топлива при движении.
Чем более качественный бензин, тем выше его октановое число. Кроме того, этот параметр сказывается и на расходе топлива при движении.
Высокооктановые бензины расходуются медленнее, что заметно нивелирует разницу в цене разного топлива.
Определяется октановое число бензина соотношением содержания изомеров октана в сравнении с количеством гептана в топливе. То есть в топливе АИ-92 содержание изооктана в смеси с гептаном составляет 92%. Следует отметить, что октановое число не определяет именно содержание, а вычисляется путем сравнения антидетонационных качеств конкретного бензина с эталонной смесью. Поэтому у некоторых специализированных видов топлива октановое число может быть больше 100. Это означает, что по устойчивости к детонации данный бензин превосходит чистый изооктан.
На показатели октанового числа влияет фракционный состав топлива (более подробно о котором мы расскажем далее). Чем больше в бензине легких фракций, тем он качественнее и безопаснее в плане детонационной составляющей.
Также изменить октановое число топлива можно путем добавления в него различных присадок. Раньше широко использовались соединения на основе свинца и этила (например, тетраэтилсвинец). Их введение в состав бензина позволяет легко превратить АИ-92 в АИ-95. Но с 2003 года из-за высокого вреда, наносимого атмосфере и окружающей среде, от использования соединений свинца в составе бензина отказались.
Также повысить октановый показатель можно добавлением этилового спирта. Но такой метод экономически невыгоден, поэтому в промышленных масштабах не применяется. Еще один способ повышения октанового показателя – добавление в бензин ацетона. Часто в качестве присадок используются соединения пропана и метана, у которых более высокая детонационная устойчивость, чем у изооктана.
Химическая стабильность бензина
Еще один важный показатель в бензине, особенно актуальный для топлива с присадками, – его химическая стабильность. С одной стороны, добавление присадок – например, метана и пропана в бензин позволяет повысить его октановое число. Но эти элементы достаточно легкие и летучие, а потому испаряются с большей скоростью и при более низких температурах, чем основная фракция топлива.
Но эти элементы достаточно легкие и летучие, а потому испаряются с большей скоростью и при более низких температурах, чем основная фракция топлива.
Нормативными требованиями установлено, что бензин должен сохранять свои физико-химические свойства в течение пяти лет – при условии соблюдения норм и правил хранения. Поэтому, если производитель вводит в топливо присадки с целью повышения его детонационной устойчивости, то должен использовать устойчивые химические соединения. В противном случае бензин довольно быстро потеряет свои качества.
На недобросовестность производителя или продавца указывает сильный специфический запах газа, который нередко присутствует на АЗС. Это значит, что метан и/или пропан, добавленные в бензин, активно испаряются, а само топливо заведомо не соответствует маркировке.
Другие показатели топлива
Одним из важных показателей ГСМ является его фракционный состав. Бензин состоит из различных нефтепродуктов – легких и тяжелых углеводородов, входящих в состав топлива в разном количестве. Именно фракционным составом в первую очередь определяются основные физико-химические параметры и эксплуатационные свойства бензина, такие как летучесть, вязкость, температура замерзания. Чем больше легких фракций в топливе, тем лучше оно испаряется и тем ниже температура его замерзания. Поэтому в условиях сверхнизких температур и сурового северного климата обычно используются специализированные бензины пониженной вязкости и с низкой температурой застывания. Стоит такой бензин дороже обычного, но в некоторых случаях его использование – неизбежная необходимость.
Именно фракционным составом в первую очередь определяются основные физико-химические параметры и эксплуатационные свойства бензина, такие как летучесть, вязкость, температура замерзания. Чем больше легких фракций в топливе, тем лучше оно испаряется и тем ниже температура его замерзания. Поэтому в условиях сверхнизких температур и сурового северного климата обычно используются специализированные бензины пониженной вязкости и с низкой температурой застывания. Стоит такой бензин дороже обычного, но в некоторых случаях его использование – неизбежная необходимость.
Еще один важный фактор, определяющий экологическую безопасность бензина, – содержание различных примесей. В основном оценивается количество соединений серы и ароматических углеводородов в бензинах. Эти вещества при сгорании образуют ядовитые соединения, которые наносят вред не только окружающей среде, но и топливной и выхлопной системе автомобиля, а также жизни и здоровью людей.
Содержание опасных примесей в бензине регламентируется соответствующими нормативными документами. Оптимальным выбором сейчас является бензин с маркировкой Евро-5, который наряду с более высококачественным топливом Евро-6 сегодня применяется в большинстве европейских стран. В России же на бензин приняты и действуют экологические стандарты Евро-4 и Евро-5.
Оптимальным выбором сейчас является бензин с маркировкой Евро-5, который наряду с более высококачественным топливом Евро-6 сегодня применяется в большинстве европейских стран. В России же на бензин приняты и действуют экологические стандарты Евро-4 и Евро-5.
Среди основных параметров следует отметить и испаряемость, которая также зависит от фракционного состава бензина. Этот показатель важен для климатических условий, в которых эксплуатируется автомобиль с бензиновым двигателем. Так для холодной полосы важно, чтобы показатель испаряемости был высоким. В противном случае будут неизбежно возникать проблемы с запуском двигателя. В жарком климате, наоборот, высокая испаряемость – это угроза взрывоопасности.
Параллельно испаряемости существует еще один значимый показатель – давление насыщенных паров. Оно дает дополнительное представление о фракционном составе и испаряемости топлива. Чем выше это значение, тем больше вероятность образования газовых пробок в бензиновых двигателях, что также представляет опасность из-за вероятности воспламенения и взрыва.
Как выбирать бензин
Правильно подобранное топливо – залог долгой и эффективной службы авто. При выборе мы советуем прислушиваться к рекомендации производителя конкретного автомобиля (и, соответственно, бензинового двигателя). Если в руководстве указано топливо с октановым показателем 95, то лучше использовать именно АИ-95, а не 92-й или 98-й бензины. В таком случае вы сможете быть уверены в надежности и стабильности работы авто.
Еще один важный момент, на который стоит обращать внимание, экологические параметры бензинов. Стандарты Евро – 4, 5 или 6 – гарантия того, что вы сможете не только беспрепятственно выезжать на авто за границу, но и залог долгой службы двигателя, топливной и выхлопной систем автомобиля.
К сожалению, оценить, насколько качественный бензин в конкретной АЗС сложно. Как уже упоминалось выше, ключевым фактором, что свидетельствует о невысоком качестве топлива, является наличие сильного запаха газа на заправке. Таким бензином авто лучше не заправлять.
Для проверки качества можно приобрести бензин, налив его в прозрачную емкость. Топливо должно быть прозрачным с легким бледно-желтым оттенком без осадков и примесей. Если добавить в бензин марганцовку, то качественное топливо не окрасится в розовый цвет. Появление же оттенка говорит о том, что в бензин добавлена вода.
Бензин – его производство, маркировка, октановое число
Бензин – сложно вспомнить что-то более привычное для автомобилиста. Ежедневно автомобили сжигают сотни тысяч литров этого топлива, однако мало кто из автовладельцев всерьез задумывался над тем, как его производят, об особенностях состава топлива и других аспектах.
Немного терминологии
Как сообщают справочники, бензином именуется смесь лёгких углеводородов разных типов:
- Ароматические;
- Олефиновые;
- Парафиновые и прочие.
Эти углеводороды обладают горючими свойствами. Температура кипения смеси варьируется от 33 до 250 °С, что зависит от применяемых присадок.
Из чего делают бензин
Схема производства бензина
Горючее выпускается на мощностях нефтеперерабатывающих заводов. Сам производственный процесс очень сложен и делится на несколько циклов.
Сначала сырая нефть поступает на предприятие по трубопроводам, закачивается в огромные резервуары, после чего отстаивается. Далее начинается промывка нефти – в нее добавляется вода, а потом пропускается электрический ток. В итоге соли оседают на дно и стенки резервуаров.
Во время последующей атмосферно-вакуумной перегонки происходит подогрев нефти и ее деление на несколько типов. Осуществляются 2 этапа обработки:
- Вакуумная;
- Термическая.
По завершении процесса первичной переработки начинается каталитический риформинг, во время которого происходит очередное очищение бензина и извлечение фракций 92-го, 95-го и 98-го бензина.
Фото: aif.ru
Это процесс, который еще называют вторичной переработкой, включает 2 основных этапа:
- Крекинг – очистка нефти от примесей серы;
- Риформинг – наделение субстанции октановым числом.

Видео: Как делают бензин из нефти. Просто о сложном
По окончании данных этапов проходит контроль качества горючего, который занимает несколько часов.
Примечательно, что отечественные заводы (в большинстве) из 1 тонны нефти получают 240 литров бензина. Остальное приходится на газ, дизтопливо, мазут и авиационное горючее.
Что такое октановое число
Эта фраза известна очень многим, однако далеко не все знают, что именно означает данный термин и почему он так важен.
Октановое число – это способность топлива (в том числе и бензина) противостоять самопроизвольному возгоранию под давлением. Иначе говоря – его детонационная стойкость.
В процессе работы двигателя поршень сжимает топливно-воздушную смесь (такт сжатия). В этот момент, когда готовая смесь находится под давлением, может произойти ее самопроизвольное воспламенение еще до того, как свеча зажигания дала искру. В народе это явления называется одним словом – «детонация». Характерным признаком детонации являются шумы в двигателе – металлический звон.
В народе это явления называется одним словом – «детонация». Характерным признаком детонации являются шумы в двигателе – металлический звон.
Следовательно, чем выше октановое число, тем выше способность горючего сопротивляться детонации.
Маркировка бензина
На АЗС можно встретить самые разные наименования, не исключая и наиболее привычные для большинства автомобилистов. Обычно бензин маркируется литерами «А» и «АИ». Их расшифровка:
- «А» – это обозначение свидетельствует, что бензин автомобильный;
- «АИ» – буква «И» означает метод, которым было определено октановое число.
Существует 2 способа определения октанового числа – исследовательский (АИ) и моторный (АМ).
Исследовательский метод – он определяется путем тестирования топлива на одноцилиндровой силовой установке, при условии переменной степени сжатия, частоте вращения коленвала в 600 об/мин, угле опережения зажигания в 13° и температуре воздуха (всасываемого) в 52 °С. Эти условия аналогичны небольшим и средним нагрузкам.
Моторный метод – его определение осуществляется на аналогичной установке, однако прочие условия другие. Температура воздуха (всасываемого) составляет 149 °С, частота вращения коленвала равна 900 об/мин, а угол опережения зажигания переменный. Такой режим аналогичен высоким нагрузкам – езда в гору, работа мотора под нагрузкой и т. д.
Следовательно, число АМ всегда ниже, нежели АИ, а разница в показаниях свидетельствует о чувствительности горючего к работе силового агрегата в разных режимах. Примечательно, что в некоторых государствах на Западе октановое число определяется как среднее между значениями «АМ» и «АИ». В РФ же обозначается только более высокое значение «АИ», что и можно увидеть на всех АЗС.
Марки бензина
Чаще всего на отечественных заправочных станциях встречаются следующие обозначения:
- Бензин АИ-98. Отличается высоким октановым числом. В отличие от АИ-95, который производится в соответствии с ГОСТом, 98-й выпускается согласно ТУ 38. 401-58-122-95, а также ТУ 38.401-58-127-95. В производстве этой марки бензина запрещено применение алкилсвинцовых антидетонаторов. Выпуск данного высокооктанового бензина осуществляется с использованием ряда компонентов – толуола, изопентана, изооктана и алкилбензина.
- Экстра АИ-95 – бензин повышенного качества, что достигается путем применения присадок антидетонационного типа. Производится из дистиллятного сырья, бензина каталитического крекинга, с добавлением изопарафиновых элементов (ароматических) и газового бензина. В составе нет свинца, что обеспечивает высокое качество бензина.
- АИ-95 – основное отличие от Экстра АИ-95 в концентрации свинца, которая выше на 30%;
- АИ-93 – делится на 2 категории: этилированный и неэтилированный. Этилированное топливо выпускается на основе бензина каталитического риформинга (мягкий режим) с добавлением в его состав толуола и алкилбензина, а также бутан-бутиленовой фракции. Неэтилированный выпускается из того же бензина каталитического риформинга (жесткий режим), с добавлением бутан-бутиленовой фракции, алкилбензина и изопентана;
- АИ-92 – наиболее распространенный на рынке бензин среднего качества, с содержанием присадок антидетонационного типа. Максимальная плотность – 0,77г/смА-923. Может быть как этилированным, так и неэтилированным;
- АИ-91 – отличается содержанием присадок антидетонационного типа. Это неэтилированный бензин с ненормированной плотностью и определенным процентом свинца в составе;
- А-80 – состав этого бензина аналогичен таковому у АИ-92. Максимальная плотность – 0,755г/смА-803;
- А-76 – обычно применяется в сельском хозяйстве. Выпускается этилированный и неэтилированный А-76 с ненормируемой плотностью. В его составе содержатся присадки разных типов (антиокислительные и антидетонационные), прямогонный бензин, а также итоговые продукты коксования, пиролиза и крекинга (термического и каталитического).
 401-58-122-95, а также ТУ 38.401-58-127-95. В производстве этой марки бензина запрещено применение алкилсвинцовых антидетонаторов. Выпуск данного высокооктанового бензина осуществляется с использованием ряда компонентов – толуола, изопентана, изооктана и алкилбензина.
401-58-122-95, а также ТУ 38.401-58-127-95. В производстве этой марки бензина запрещено применение алкилсвинцовых антидетонаторов. Выпуск данного высокооктанового бензина осуществляется с использованием ряда компонентов – толуола, изопентана, изооктана и алкилбензина. Максимальная плотность – 0,77г/смА-923. Может быть как этилированным, так и неэтилированным;
Максимальная плотность – 0,77г/смА-923. Может быть как этилированным, так и неэтилированным;Видео: Аи-92 или Аи-95? Разгон до 100км и расход топлива на Mazda Demio (Ford Festiva Mini Wagon)
Какой бензин заливать?
Многие ищут ответ на этот вопрос, чтобы ненароком не навредить двигателю. В данном случае все просто – требования к топливу указаны в инструкции по эксплуатации конкретного автомобиля, а также продублированы на обратной стороне лючка бензобака. Если производитель в качестве рекомендуемого топлива указал АИ-95, то заливать нужно именно его, а заправляться 92-м можно только на свой страх и риск. Однако стоит помнить, что в мануале и на этикетке может быть указано как октановое число, так и марка топлива.
В данном случае все просто – требования к топливу указаны в инструкции по эксплуатации конкретного автомобиля, а также продублированы на обратной стороне лючка бензобака. Если производитель в качестве рекомендуемого топлива указал АИ-95, то заливать нужно именно его, а заправляться 92-м можно только на свой страх и риск. Однако стоит помнить, что в мануале и на этикетке может быть указано как октановое число, так и марка топлива.
Также в мануале могут быть записаны разные типы бензина. Например:
- АИ-92 – допустимый;
- АИ-95 – рекомендуемый;
- АИ-98 – для улучшения характеристик.
Как видно, заливать в бак необходимо только рекомендуемое производителем авто топливо. Впрочем, использование бензина с более высоким октановым числом никакого вреда двигателю не нанесет. Ведь чем выше октановое число, тем медленнее скорость горения и больше КПД топлива, что благотворно сказывается на отдаче двигателя, экономичности и других моментах. Как правило, прибавка в мощности и экономичности достигает 7%. Кроме того, современные машины комплектуются ЭБУ, которые учитывают качество горючего и его октановое число, корректируя настройки.
Кроме того, современные машины комплектуются ЭБУ, которые учитывают качество горючего и его октановое число, корректируя настройки.
Это значит, что в бак современного автомобиля с атмосферным мотором необходимо заливать АИ-95 на качественной АЗС. В крайнем случае, допускается АИ-92. Также можно ориентироваться на степень сжатия – если она ниже 10 ед., можно заливать АИ-92. Если выше – только 95-й.
Что касается турбированных двигателей, то для них рекомендуемое топливо – АИ-98 или Экстра АИ-95, но не АИ-92.
Можно ли смешивать бензин?
Этим вопросом задаются многие. В целом от смешивания горючего с разным октановым числом ничего катастрофического не произойдет, но только если смешивать рекомендуемый бензин с более высоким (по октановом числу). К примеру, рекомендуемый для машины 92-й смешать с 95-м. Однако понижать не нужно. Также стоит помнить, что плотность у бензина с разным октановым числом различается, так что его смешивания может вообще не произойти – горючее с более высоким октановым числом просто окажется вверху бака, а с низким внизу.
В целом, чтобы сохранить двигатель, рекомендуется не экономить, заправляться только на сертифицированных станциях крупных сетей (не франшиза) и лить в бак бензин с октановым числом, рекомендованным изготовителем (но не ниже).
данных — топливо для искусственного интеллекта | Кристиан Эл
Отличное качество данных так же важно для успеха вашего решения ИИ, как и качество программного обеспечения для ваших критически важных программ. Навыки работы с данными необходимы в вашем путешествии по ИИ, и они необходимы для разработки этических решений ИИ.
В сегодняшней дискуссии об искусственном интеллекте много говорится и пишется о нейронных сетях и платформах искусственного интеллекта, которые обеспечивают возможности нейронных сетей. Тем не менее, мы считаем, что данные, которые подпитывают ИИ, нуждаются в более подробном обсуждении. Именно данные обучают искусственный интеллект и определяют его назначение. ИИ воздействует на данные, а качество данных определяет качество искусственного интеллекта. Нужно еще многое узнать и улучшить в том, как правильно работать с данными, и необходимы дополнительные обсуждения и исследования, чтобы найти способы определения, сбора, реализации и контроля потоков данных для получения положительных и надежных результатов в ИИ. Только если вы используете правильные данные и только если у вас достаточно данных, итоговые решения искусственного интеллекта могут привести к ценным решениям, имеющим положительное влияние на ваших пользователей и на ваш бизнес. Любая предвзятость в данных обучения будет влиять на решение вашей системы ИИ, что приведет к тому, что решения будут неверными, неточными и непоследовательными. Неправильные данные могут легко привести к этически неправильному и опасному ИИ. В этой статье мы расскажем, как работать с данными в ИИ.
Нужно еще многое узнать и улучшить в том, как правильно работать с данными, и необходимы дополнительные обсуждения и исследования, чтобы найти способы определения, сбора, реализации и контроля потоков данных для получения положительных и надежных результатов в ИИ. Только если вы используете правильные данные и только если у вас достаточно данных, итоговые решения искусственного интеллекта могут привести к ценным решениям, имеющим положительное влияние на ваших пользователей и на ваш бизнес. Любая предвзятость в данных обучения будет влиять на решение вашей системы ИИ, что приведет к тому, что решения будут неверными, неточными и непоследовательными. Неправильные данные могут легко привести к этически неправильному и опасному ИИ. В этой статье мы расскажем, как работать с данными в ИИ.
Первой остановкой в любом проекте ИИ должно быть определение цели проекта.
- Зачем нужен проект?
- Чего вы пытаетесь достичь?
- Какие решения должен принимать ИИ?
- Почему ИИ является правильным выбором для решения этой проблемы и какие есть альтернативы?
Ответы на эти вопросы определят влияние использования ИИ на ваш проект, они позволят вам измерить окупаемость ваших инвестиций (ROI) и обеспечат решение действительно важной проблемы. Это необходимо для обоснования необходимых ресурсов и усилий, которые необходимо предпринять. Формулировка цели также определит данные и качество данных, которые необходимы для обучения и работы вашего ИИ. В этой статье мы сосредоточимся на использовании ИИ для принятия предопределенного решения, поэтому принятое решение определяет необходимые данные. Однако существуют и другие типы проектов ИИ, не рассматриваемые в этой статье, в которых вы используете ИИ для понимания ваших данных, обнаружения шаблонов в существующих данных или извлечения знаний из ваших данных.
Это необходимо для обоснования необходимых ресурсов и усилий, которые необходимо предпринять. Формулировка цели также определит данные и качество данных, которые необходимы для обучения и работы вашего ИИ. В этой статье мы сосредоточимся на использовании ИИ для принятия предопределенного решения, поэтому принятое решение определяет необходимые данные. Однако существуют и другие типы проектов ИИ, не рассматриваемые в этой статье, в которых вы используете ИИ для понимания ваших данных, обнаружения шаблонов в существующих данных или извлечения знаний из ваших данных.
При определении цели вашего проекта важным первым шагом является определение необходимых данных и просмотр доступных данных.
- Сколько данных доступно и каково их качество?
- Какие данные отсутствуют и как их можно сгенерировать или добавить в проект?
- Как вы гарантируете, что данные не будут предвзятыми?
- Соблюдаются ли в вашем проекте этические соображения?
Убедитесь, что ваш проект и данные указаны правильно. ИИ, обученный распознавать кошек по фотографиям, не сможет распознавать лошадей. Если это неправильно помечено, ваш ИИ может быть неправильно использован или неправильно истолкован и даст неверные результаты. Это очень важный фактор, позволяющий заставить ваш ИИ вести себя наиболее полезным и этичным образом.
ИИ, обученный распознавать кошек по фотографиям, не сможет распознавать лошадей. Если это неправильно помечено, ваш ИИ может быть неправильно использован или неправильно истолкован и даст неверные результаты. Это очень важный фактор, позволяющий заставить ваш ИИ вести себя наиболее полезным и этичным образом.
Возьмем простой пример распознавания речи, чтобы описать некоторые основные понятия и изложить подход к работе с данными в ИИ. Здесь мы разрабатываем приложение подкаста для пожилых людей. Наша целевая аудитория — люди в возрасте, у которых много времени, их зрение не так хорошо для чтения и они не очень разбираются в технологиях. Мы предполагаем, что люди будут управлять приложением с помощью голоса через смартфон или смарт-динамик. Используя определенный набор команд, мы хотим, чтобы приложение управлялось голосом людей. Мы хотим наслаждаться часами развлечений, не возясь с кнопками и элементами управления. Понимание голоса — хорошая область для использования ИИ, поскольку данные могут быть очень неструктурированными, в зависимости от используемых слов, акцентов, четкости голоса, и это лишь некоторые факторы. Цель вашего ИИ — понять, что говорят пожилые люди, интерпретировать смысл и преобразовать это в команды, которые запускают функцию в приложении.
Цель вашего ИИ — понять, что говорят пожилые люди, интерпретировать смысл и преобразовать это в команды, которые запускают функцию в приложении.
Первый шаг — определить, какие данные необходимы. Мы придумываем несколько способов произнесения каждой команды, поскольку у людей есть разные способы произнесения слов для достижения одной и той же цели. Чем лучше и тщательнее мы это подготовим, тем лучше будет опыт для наших пользователей. Когда приложение используется, способ записи пользовательского ввода (и, следовательно, создания данных) будет осуществляться через микрофон выбранного нами аппаратного устройства (датчика).
Создание данных с датчиков. Теперь нам нужно найти способ понять речевые данные. Программирование традиционным способом слишком сложно и чревато ошибками, поэтому мы развернем ИИ, чтобы понять, что говорит пользователь. Датчик микрофона будет собирать голосовые данные от пользователей и предоставлять наш поток данных для подачи в наш ИИ. ИИ будет использовать голосовые данные, чтобы решить, что пользователь хочет сделать. Решение будет состоять в том, чтобы выполнить команду в нашем приложении на основе ввода голосовых данных. Для этого нам нужно обучить ваш ИИ понимать голосовые данные, особенно голоса пожилых людей и их особую манеру речи.
Решение будет состоять в том, чтобы выполнить команду в нашем приложении на основе ввода голосовых данных. Для этого нам нужно обучить ваш ИИ понимать голосовые данные, особенно голоса пожилых людей и их особую манеру речи.
Чтобы обучить ИИ, нам нужно получить обучающие данные и пометить их (человек, говорящий «старт», переводится как «старт»). Теперь нам нужно много людей, которые начинают говорить по-своему, акценты, интонации. Чем лучше наши тренировочные данные и чем больше тренируется ИИ, тем лучше будет работать наш ИИ. Как мы можем получить обучающие данные для нашего конкретного варианта использования? Есть несколько способов получить помеченные обучающие данные, и наша первая задача — подумать о наиболее эффективном способе их получения для нашего проекта. Давайте рассмотрим некоторые возможности.
- Мы сами можем записать образцы голоса. Для этого мы можем навестить пожилых людей и попросить их произнести определенные нами команды в различных вариациях. Для каждой записи мы маркируем команду, сопоставляя голосовые данные с меткой. Это может занять довольно много времени, а результаты ограничены типом людей, которых мы записываем.
- Мы можем искать видео на YouTube, содержащие нецензурную лексику, находить соответствующие разделы, вырезать их и соответствующим образом маркировать.
- Мы могли бы поискать аудиокниги, которые читают пожилые люди. Здесь мы можем получить доступ как к письменным, так и к аудиофайлам. Это позволит нам написать скрипт для поиска нужного раздела, а затем мы сможем идентифицировать и пометить эти разделы соответствующим образом.
- Мы также можем искать брокеров данных, которые могут предоставить нам определенные помеченные данные.
- Мы можем попросить поставщиков услуг данных создать эти данные для нас.
- Многие страны с низкой стоимостью рабочей силы сейчас создают службы данных, которые можно использовать для классификации и искусственного интеллекта.
 Это может занять довольно много времени, а результаты ограничены типом людей, которых мы записываем.
Это может занять довольно много времени, а результаты ограничены типом людей, которых мы записываем. После того, как вы собрали эти данные, пришло время подготовить их для обучения ИИ. Прежде чем мы это сделаем, нам нужно убедиться, что наших данных достаточно и они имеют нужное качество.
Прежде чем мы это сделаем, нам нужно убедиться, что наших данных достаточно и они имеют нужное качество.
- Есть ли у нас множество способов сказать что-то?
- У нас разные тона и пол голоса?
- У нас есть варианты акцентов?
- Данные очищены от фоновых шумов?
Все это повлияет на качество нашего ИИ. Мы тщательно анализируем наши данные, затем делаем их согласованными и преобразуем в правильный формат. Мы уменьшаем и очищаем данные (убедимся, что у нас есть только соответствующие разделы, что фоновые шумы отфильтрованы), разлагаем данные (решаем, нужны ли нам слова или предложения). Мы масштабируем данные (чтобы они имели одинаковый объем). При подготовке наших обучающих данных каждый из этих шагов рассматривается и выполняется с большой осторожностью. С этими данными мы можем затем обучить наш ИИ.
Как только наш ИИ будет хорошо обучен, некоторые из этих функций управления данными могут быть автоматизированы (например, изменение масштаба), поскольку мы вводим данные в ваш ИИ в режиме реального времени.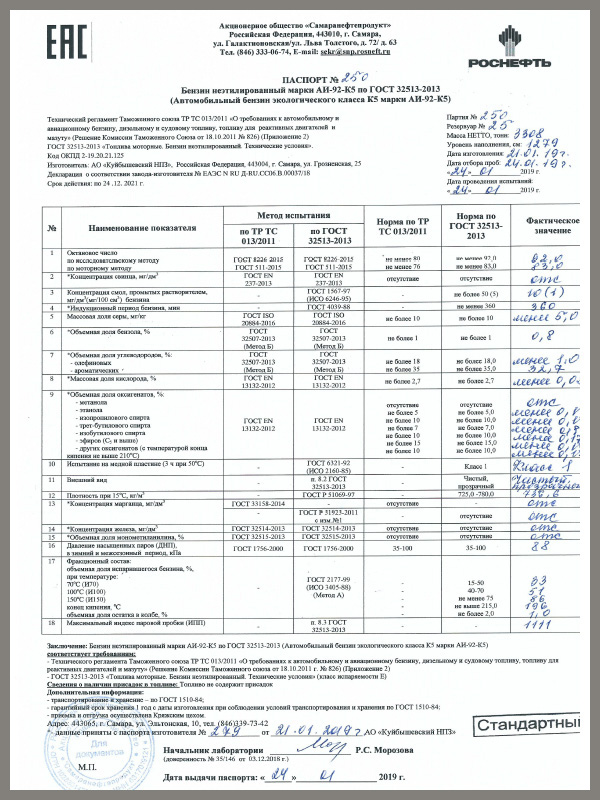 А вот для обучающих данных мы рекомендуем делать это с большой осторожностью, шаг за шагом. Во многих проектах начальное обучение ИИ — достаточно ручной процесс.
А вот для обучающих данных мы рекомендуем делать это с большой осторожностью, шаг за шагом. Во многих проектах начальное обучение ИИ — достаточно ручной процесс.
Подготовка данных требует большой работы, и вы должны быть очень осторожны, чтобы сделать все правильно, поскольку ваш ИИ будет учиться только на предоставленных вами обучающих данных. Плохое качество данных будет означать низкую производительность ИИ. Если ваши данные предвзяты, ваш ИИ будет предвзят и примет неверные решения. Помимо качества, вы также должны учитывать этику. Если вы учитываете только мужские голоса в своих тренировочных данных, ваш ИИ может ошибаться в понимании женщин. Если вы учитываете только некоторые акценты, другие различные акценты могут быть поняты неправильно. Это может не быть большой проблемой для нашего приложения для подкастов, но это определенно большая проблема, если кто-то принимает важные жизненные решения на основе ИИ, как, например, в приложении для экстренных случаев.
После того, как данные для обучения подготовлены, пришло время обучить нейронную сеть. Для этого мы настраиваем нейронную сеть по нашему выбору. Существует все больше вариантов платформ ИИ от различных игроков рынка, таких как IBM, Amazon, Google, Microsoft. У многих уже есть готовые сервисы для речевых данных, некоторые сервисы уже в определенной степени предварительно обучены. Подача помеченных обучающих данных проста и не требует много времени. Как только это будет сделано, мы готовы проверить качество нашего ИИ. Мы отправляем неразмеченные данные и наблюдаем, как наш ИИ принимает решения. Это всегда будет давать нам уровень уверенности, и на его основе мы можем измерить правильность нашего обученного ИИ. Сравнение этого с реальными известными данными даст нам представление о том, правильно ли ведет себя наш ИИ или нам нужно больше и более качественные данные для его обучения. В нашем простом примере это процесс, требующий большого человеческого вмешательства, внимания и усилий. Во многих проектах по ИИ мы видели, что нельзя недооценивать время и усилия по обучению ИИ.
Для этого мы настраиваем нейронную сеть по нашему выбору. Существует все больше вариантов платформ ИИ от различных игроков рынка, таких как IBM, Amazon, Google, Microsoft. У многих уже есть готовые сервисы для речевых данных, некоторые сервисы уже в определенной степени предварительно обучены. Подача помеченных обучающих данных проста и не требует много времени. Как только это будет сделано, мы готовы проверить качество нашего ИИ. Мы отправляем неразмеченные данные и наблюдаем, как наш ИИ принимает решения. Это всегда будет давать нам уровень уверенности, и на его основе мы можем измерить правильность нашего обученного ИИ. Сравнение этого с реальными известными данными даст нам представление о том, правильно ли ведет себя наш ИИ или нам нужно больше и более качественные данные для его обучения. В нашем простом примере это процесс, требующий большого человеческого вмешательства, внимания и усилий. Во многих проектах по ИИ мы видели, что нельзя недооценивать время и усилия по обучению ИИ.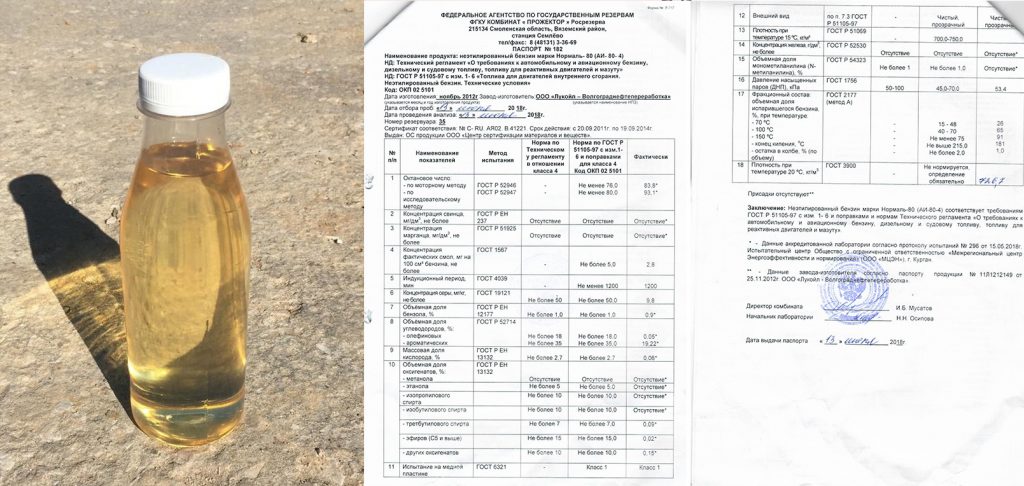
После первоначального обучения ИИ мы можем использовать ИИ в нашем приложении, и пользователи смогут начать с ним взаимодействовать. Качество ИИ будет зависеть от количества и качества наших обучающих данных. Часто имеет смысл настроить приложение таким образом, чтобы ИИ со временем улучшался. Обратите внимание, что ИИ учится только с обратной связью, поэтому мы должны встроить этот цикл обратной связи в наше приложение, чтобы ИИ продолжал учиться на данных в реальном времени. Это еще один важный шаг, который не всегда легко выполнить, поэтому давайте рассмотрим некоторые варианты его выполнения для нашего примера. Один из способов получить обратную связь о решениях ИИ — попросить пользователя принять участие. В нашем приложении для подкастов мы могли бы создать кнопку обратной связи, которую пользователи нажимают, если приложение не понимает их правильно. Эта информация может быть направлена группе данных, которая затем просматривает данные и передает их в ИИ для обучения (возможно, создавая дополнительные отклонения данных для оптимального обучения). Если пользователи действительно вовлечены, они также могут провести обучение и сами обозначить свои намерения. Это часто делается с вовлеченными ранними пользователями (ведущими пользователями), у которых есть высокая мотивация улучшить приложение или услугу. Делать это с обычными пользователями не рекомендуется, так как они устают, если их постоянно просят улучшить основную функцию приложения и просто ожидают, что приложение будет работать. В качестве альтернативы ваша группа данных может прослушивать речевые данные пользователей, чтобы увидеть и оценить, где ИИ нуждается в улучшении, пометить данные и использовать их для оптимизации ИИ на основе реальных данных об использовании. Эта задача также может быть передана на аутсорсинг растущему сектору компаний, предоставляющих услуги данных.
Если пользователи действительно вовлечены, они также могут провести обучение и сами обозначить свои намерения. Это часто делается с вовлеченными ранними пользователями (ведущими пользователями), у которых есть высокая мотивация улучшить приложение или услугу. Делать это с обычными пользователями не рекомендуется, так как они устают, если их постоянно просят улучшить основную функцию приложения и просто ожидают, что приложение будет работать. В качестве альтернативы ваша группа данных может прослушивать речевые данные пользователей, чтобы увидеть и оценить, где ИИ нуждается в улучшении, пометить данные и использовать их для оптимизации ИИ на основе реальных данных об использовании. Эта задача также может быть передана на аутсорсинг растущему сектору компаний, предоставляющих услуги данных.
Этот небольшой пример иллюстрирует важность данных для ИИ. Хотя часто существуют различные варианты получения данных, очень важно получить правильные данные, подготовить их для ИИ и убедиться, что мы понимаем и сводим к минимуму систематическую ошибку в данных. К подготовке данных следует подходить с большой осторожностью, и часто требуются большие усилия, чтобы сделать их правильными. Помните об этических последствиях, если данные необъективны. После того, как ИИ заработает, важно определить способы его улучшения и обучения с течением времени. Все это требует сильной цели для ИИ. В противном случае усилия могут перевесить выгоды, которые могут быть достигнуты, и проект потерпит неудачу.
К подготовке данных следует подходить с большой осторожностью, и часто требуются большие усилия, чтобы сделать их правильными. Помните об этических последствиях, если данные необъективны. После того, как ИИ заработает, важно определить способы его улучшения и обучения с течением времени. Все это требует сильной цели для ИИ. В противном случае усилия могут перевесить выгоды, которые могут быть достигнуты, и проект потерпит неудачу.
Подготовка данных необходима для обучения и принятия решений ИИ в режиме реального времени. Это должно быть вашей самой важной задачей в любом проекте ИИ. Эта задача специфична для варианта использования и компании, создающей вариант использования. Это должны делать вы и ваша команда, и это не относится к платформам искусственного интеллекта, которые доступны сегодня. Это будет отличать ваш ИИ от других, независимо от того, какую платформу ИИ вы используете. Сегодня существует заблуждение, что нейронная сеть является ключом к успеху вашего ИИ, мы считаем, что качество обучающих данных является ключом.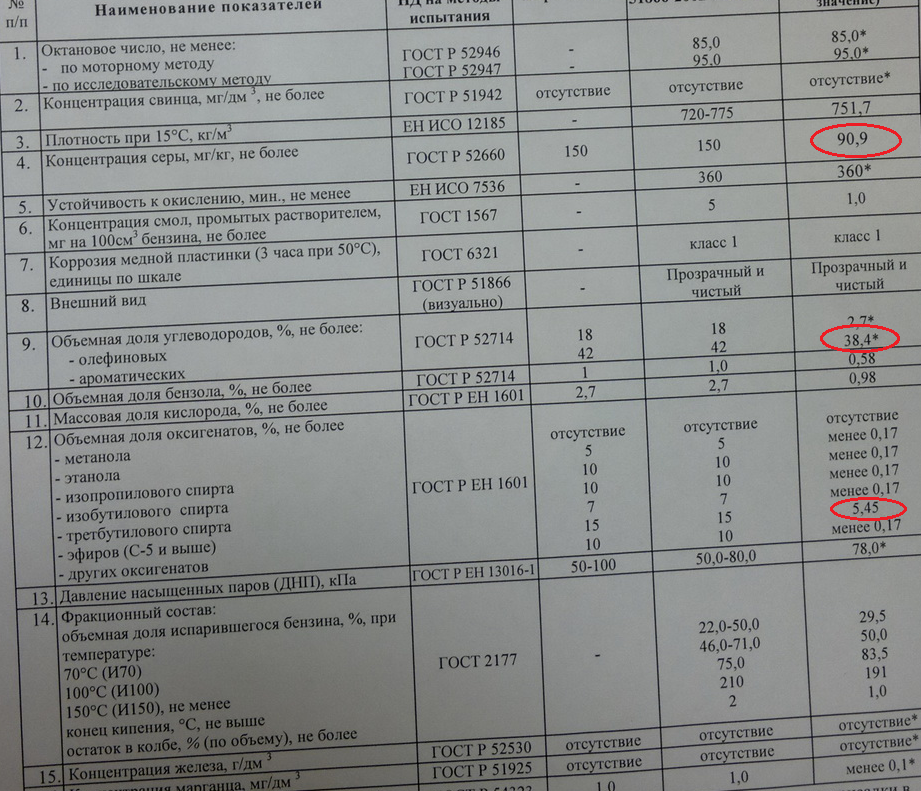 Можно предположить, что нейросеть — это просто черный ящик, и со временем она будет совершенствоваться. Ключом к успеху вашего ИИ является качество и количество ваших данных. Это ваша самая большая ответственность, и это ваша самая большая возможность. Это окупается, если вы потратите много времени и усилий на подготовку данных. Хорошие и непредвзятые данные приведут к хорошему и беспристрастному ИИ. Стоит повторить это для себя и для своей команды. Все дело в данных, данных, данных…
Можно предположить, что нейросеть — это просто черный ящик, и со временем она будет совершенствоваться. Ключом к успеху вашего ИИ является качество и количество ваших данных. Это ваша самая большая ответственность, и это ваша самая большая возможность. Это окупается, если вы потратите много времени и усилий на подготовку данных. Хорошие и непредвзятые данные приведут к хорошему и беспристрастному ИИ. Стоит повторить это для себя и для своей команды. Все дело в данных, данных, данных…
При подготовке данных мы рекомендуем использовать следующий подход из 7 шагов, чтобы ответить на наиболее важные вопросы:
Иллюстрация: как подготовить данные для ИИ1. Сформулируйте проблему
- Какую проблему вы пытаетесь решить?
- Почему ее нельзя решить традиционными средствами?
- Какие решения должен принимать ИИ?
- Какая польза от решения этой проблемы?
- Сколько усилий я могу приложить для достижения положительного ROI?
2. Определите необходимые данные
Определите необходимые данные
- Какие данные необходимы для надежного принятия этих решений?
- Какие другие данные и факторы влияют на эти данные?
- Какие могут быть важные корреляции в данных и с внешними данными?
- Где в данных могут существовать или возникать систематические ошибки?
3. Квалифицируйте свои данные и определите минимальную точность предсказания
- Какие данные у вас есть?
- Доступны ли исторические данные и каково качество этих данных?
- Какова систематическая ошибка в имеющихся у вас данных?
- Какова минимальная точность прогноза, которая делает решение, принятое ИИ, ценным?
4. Источник недостающих данных
- Можете ли вы создать недостающие данные (например, путем изменения процессов или поведения, добавления датчиков)?
- Можно ли получить данные из другого источника?
- Можно ли приобрести недостающие данные?
- Можете ли вы попросить кого-нибудь создать для вас недостающие данные?
- Какие данные вы сможете получать в будущем?
5. Отформатируйте данные и сделайте их согласованными
Отформатируйте данные и сделайте их согласованными
- Как получить доступ к данным?
- Как создать согласованный формат для ИИ для чтения ваших данных (формат ввода должен быть согласованным для всех наборов данных)?
- Как вы создаете поток данных из всех данных для ввода в ваш ИИ?
6. Сокращение, декомпозиция и очистка данных
- Какие данные или атрибуты будут наиболее важными для принятия решения?
- Какие данные могут быть помехой или иметь приоритет над важными данными и должны быть удалены?
- Какие атрибуты точно не нужны для принятия решения (удалить)?
- В каких записях отсутствуют данные или они могут быть неверными или неполными?
- Как можно агрегировать данные или добавить дополнительные данные?
7. Измените масштаб данных
- Ваши данные представлены в разных масштабах?
- Могут ли различные масштабы повлиять на решение или качество вашего ИИ?
- Как вы можете масштабировать или нормализовать свои данные (чтобы передать оптимизирующую шкалу в ваш ИИ)?
Как подчеркивалось выше, это ваш шанс выделиться. Ваши данные — это то, что отличает вас от других, поэтому мы рекомендуем проявлять большую осторожность при выполнении этого процесса. Хотя это, безусловно, требует больших усилий, они будут определять качество вашего ИИ, ваших данных, вашего управления данными и вашего успеха.
Ваши данные — это то, что отличает вас от других, поэтому мы рекомендуем проявлять большую осторожность при выполнении этого процесса. Хотя это, безусловно, требует больших усилий, они будут определять качество вашего ИИ, ваших данных, вашего управления данными и вашего успеха.
Данные — это ваша самая большая ответственность в любом проекте ИИ, поскольку они определяют решения, которые принимает ИИ. Поскольку данные используются для обучения ИИ, они будут основой для каждого решения, которое будет принимать ИИ. Таким образом, самая важная обязанность состоит в том, чтобы получить правильные данные. В хорошо управляемом проекте ИИ все заинтересованные стороны должны быть хорошо осведомлены об этом, и руководитель проекта должен сделать это приоритетом. Хотя это не является исключительной обязанностью отдельных ролей, таких как разработчик нейронной сети, специалист по данным, инженер данных или менеджер проекта, все должны осознавать важность данных для успеха и воздействия проекта. Мы рекомендуем назначить кого-то на роль управления данными, и эта роль должна учитывать долгосрочную перспективу проекта и данных. Вы должны учитывать юридические и этические аспекты вашего ИИ. Будьте особенно внимательны при проверке, отслеживании и документировании происхождения и идентичности используемых данных. Когда ИИ принимает решение, его можно отследить только по данным, которые использовались для его обучения. Любые юридические, этические или даже усилия по оптимизации могут потребовать понимания происхождения и идентичности данных.
Мы рекомендуем назначить кого-то на роль управления данными, и эта роль должна учитывать долгосрочную перспективу проекта и данных. Вы должны учитывать юридические и этические аспекты вашего ИИ. Будьте особенно внимательны при проверке, отслеживании и документировании происхождения и идентичности используемых данных. Когда ИИ принимает решение, его можно отследить только по данным, которые использовались для его обучения. Любые юридические, этические или даже усилия по оптимизации могут потребовать понимания происхождения и идентичности данных.
Создавая свою организацию на будущее, вы должны будете сделать данные ключевым элементом своей стратегии. Без четкого представления о данных и о том, как их можно использовать, вашей организации может быть сложно реализовать свое видение ИИ. Вам также придется инвестировать в компетентность в области данных и разрушить разрозненность ИТ и бизнеса, чтобы достичь общего видения и усилий. Данные — это то, где все части вашей организации должны будут работать вместе, и для их выполнения потребуется много знаний.
Рост вычислительных мощностей, систем хранения данных, подключений и развертывание датчиков различных типов привели к взрывному росту доступности данных, с которыми часто невозможно справиться традиционными средствами и методами. Так называемые большие данные и аналитика больших данных начали решать эту задачу, чтобы работать с большим количеством данных из различных источников, добавляя дополнительные внешние источники данных, обмениваясь данными, запрашивая данные, визуализируя и сохраняя данные. Многие методы аналитики начинают ориентироваться на большие данные, и предпринимаются попытки улучшить прогнозы, полученные на основе больших данных, часто с использованием ИИ. Поскольку данные — это топливо для ИИ, большие данные — это важная разработка и возможность наблюдать и использовать. Однако тенденция добавлять слишком много данных в ИИ может привести к ухудшению качества решения ИИ. Поэтому важно использовать преимущества больших данных и аналитики для подготовки ваших данных для ИИ, а также для обеспечения и измерения качества, но не увлекайтесь добавлением данных или сложности в свои проекты ИИ. Большинство проектов ИИ, которые в основном представляют собой узкие проекты искусственного интеллекта, не требуют больших данных, чтобы обеспечить свою ценность. Им просто нужно хорошее качество данных и большое количество записей.
Большинство проектов ИИ, которые в основном представляют собой узкие проекты искусственного интеллекта, не требуют больших данных, чтобы обеспечить свою ценность. Им просто нужно хорошее качество данных и большое количество записей.
С появлением данных и проектов данных, а также распространением ИИ растет число инструментов, которые помогут вам подготовить данные для ИИ. Лучше всего искать в Интернете текущие инструменты, варианты их использования и рекомендации по их использованию. В источниках было предоставлено несколько ссылок. Некоторые из инструментов тесно интегрированы с платформами ИИ, поэтому ваш первый выбор — искать инструменты, предоставляемые платформами, которые вы используете для ИИ. Примерами являются DataPrep от Google и Data Refinery от IBM. Эти инструменты предлагают консоли управления для управления вашими данными. Они позволяют вам добавлять различные источники данных, рассчитывать и визуализировать состояние ваших данных, позволяют добавлять данные в ваши записи, среди многих других функций. Все инструменты требуют некоторых специальных ноу-хау, хотя имеется много учебных материалов для самостоятельного изучения. Также обратите внимание на растущее число консультантов, которые могут помочь в подготовке ваших данных.
Все инструменты требуют некоторых специальных ноу-хау, хотя имеется много учебных материалов для самостоятельного изучения. Также обратите внимание на растущее число консультантов, которые могут помочь в подготовке ваших данных.
К сожалению, многое может пойти не так с данными в вашем проекте ИИ. Мы видим самую большую ошибку в отсутствии доступности данных или возможности получить правильные данные для ИИ. Компании часто попадают в ловушку, думая, что у них есть все данные, но опыт показывает, что данные часто недоступны, недоступны, не подлежат хранению, неполны или необъективны. Чтобы преодолеть этот недостаток и получить правильные данные для вашего ИИ, требуется сильное видение и поддержка руководства.
После запуска проекта еще многое может пойти не так. Отсутствие качества или правильности решений в основном может быть связано с отсутствием усилий по отбору и подготовке данных и обучению ИИ. Использование неправильных источников, непонимание зависимостей данных, отсутствие очистки данных, отсутствие достаточного количества данных для обучения, предвзятые данные — это лишь несколько областей, сильно влияющих на качество решений ИИ.
Поэтому, пожалуйста, сосредоточьтесь на одном: получить правильные данные.
Эта статья написана Шарадом Ганди и Кристианом Эль в рамках серии AI&U™ (Искусственный интеллект и ВЫ). Следите за будущими статьями о том, как понимать, изучать, развертывать и использовать ИИ для себя и своей организации. Наша книга AI&U была опубликована в 2017 году. Мы также предлагаем семинары для клиентов, чтобы помочь компаниям начать преобразование своего бизнеса с помощью ИИ.
Свяжитесь с нами по адресу www.ai-u.org
- Подготовка набора данных для машинного обучения: 8 основных методов, которые сделают ваши данные лучше, https://www.altexsoft.com/blog/datascience/preparing-your-dataset-for-machine-learning-8-basic-techniques -that-make-your-data-better/
- IBM Watson Services, https://console.bluemix.net/developer/watson/services
- Разработка стратегии машинного обучения, https://www.altexsoft.com/ blog/datascience/machine-learning-strategy-7-steps/
- Большие данные, Википедия https://en. wikipedia.org/wiki/Big_data
- IBM Data Refinery, https://www.ibm.com/cloud/data-refinery?S_PKG=&cm_mmc=Search_Google-_-Analytics_Watson+Data+Platform-_-WW_DE-_-+Data++Preparation_Broad_&cm_mmca1=000019OO&cm_mmca2= 100006501&cm_mmca7=20229&cm_mmca8=kwd-313315197543&cm_mmca9=95236ac3-c383-4292-8bd8-c18eb727e3ed&cm_mmca10=230276596521&cm_mmca11=b&mkwid=95236ac3-c383-4292-8bd8-c18eb727e3ed%7C456%7C196491&cvosrc=ppc.google.%2Bdata%20%2Bpreparation&cvo_campaign=000019OO&cvo_crid=230276596521&Matchtype=b&gclid=Cj0KCQiAp8fSBRCUARIsABPL6JZwh5NxB5w47tGV1cDH6mm-nRbvGsAWQAv6cusSTlR62Y-Qf1cdoj4aAsQXEALw_wcB
- Google Cloud Data Prep, https://cloud.google.com/dataprep/
- Top 38 data preparation tools and plattforms https://www.predictiveanalyticstoday.com/data-preparation -tools-and-platforms/
- https://machinelearningmastery.com/how-to-prepare-data-for-machine-learning/
- http://download.microsoft.com/download/A/6/1 /A613E11E-8F9C-424A-B99D-65344785C288/microsoft-machine-learning-algorithm-cheat-sheet-v6. pdf
- Инфографика http://download.microsoft.com/download/0/5/A/05AE6B94-E688-403E-90A5-6035DBE9EEC5/ основы машинного обучения-инфографика-с-алгоритмами-примерами.pdf
- https://www.altexsoft.com/blog/datascience/preparing-your-dataset-for-machine-learning-8-basic-techniques-that -сделайте-ваши-данные-лучше/
 wikipedia.org/wiki/Big_data
wikipedia.org/wiki/Big_data pdf
pdfGE Интеграция искусственного интеллекта для создания обратной конструкции газовой турбины с учетом характеристик
Механика и дизайн, Искусственный интеллект
- Исследователи GE разрабатывают среду обратного проектирования с поддержкой искусственного интеллекта (ИИ) и машинного обучения (МО), которая позволяет использовать показатели производительности для создания более оптимизированных конструкций аэродинамических компонентов промышленных газовых турбин (IGT)
- Проект направлен на сокращение времени цикла проектирования на 30-50% или с 1 года до нескольких месяцев
- Партнерство с Университетом Нотр-Дам и GE Gas Power по проекту
- Новый набор цифровых инструментов поможет вывести эффективность электростанций с комбинированным циклом на новый уровень
NISKAYUNA, NY — 24 июня 2020 г. — Стремясь сделать новые показатели производительности основным фактором при разработке более чистых и эффективных аэродинамических энергетических систем, GE Research, подразделение GE по разработке технологий, получило первый этап двухлетнего проекта стоимостью 2,1 миллиона долларов США через ARPA-E DIFFERENTIATE ( D ESIGN I NTELLIGENCE F OSTERING F ORMidable E NERGY R EDUCTION и E NABLING A AVEL T OTALLY I MPACTFUFFUL A TWARD 3. E nhancements) для создания управляемой искусственным интеллектом обратимой нейронной сети, которая может напрямую преобразовывать эти показатели в оптимизированные проекты.
— Стремясь сделать новые показатели производительности основным фактором при разработке более чистых и эффективных аэродинамических энергетических систем, GE Research, подразделение GE по разработке технологий, получило первый этап двухлетнего проекта стоимостью 2,1 миллиона долларов США через ARPA-E DIFFERENTIATE ( D ESIGN I NTELLIGENCE F OSTERING F ORMidable E NERGY R EDUCTION и E NABLING A AVEL T OTALLY I MPACTFUFFUL A TWARD 3. E nhancements) для создания управляемой искусственным интеллектом обратимой нейронной сети, которая может напрямую преобразовывать эти показатели в оптимизированные проекты.
В настоящее время сложные аэродинамические энергетические компоненты, такие как лопатки газовых турбин, имеют чрезвычайно длительное время расчетного цикла, превышающее год, что требует компромисса между стоимостью, производительностью и надежностью. Исследователи GE вместе с подразделением GE Gas Power и Университетом Нотр-Дам стремятся разработать и продемонстрировать новую среду проектирования с поддержкой искусственного интеллекта и машинного обучения, которая занимает вдвое меньше времени и почти полностью определяется желаемыми показателями производительности для реализации проекта. компонентов аэродинамической энергии на совершенно новый уровень.
Исследователи GE вместе с подразделением GE Gas Power и Университетом Нотр-Дам стремятся разработать и продемонстрировать новую среду проектирования с поддержкой искусственного интеллекта и машинного обучения, которая занимает вдвое меньше времени и почти полностью определяется желаемыми показателями производительности для реализации проекта. компонентов аэродинамической энергии на совершенно новый уровень.
Саян Гош, ведущий инженер отдела вероятностного проектирования и руководитель проекта, объяснил, что команда создает инфраструктуру машинного обучения для вероятностного обратного проектирования — Pro-ML IDeAS, в которой используется инвертируемая нейронная сеть, управляемая искусственным интеллектом, для преодоления множества итераций проектирования и преодоления трудностей, которые обычно требуют инженерных знаний во многих сложных функциональных пространствах для решения. «Это существенно изменит парадигму проектирования газовых турбин, позволив нам исследовать и открывать новые кривые обучения, которые ранее были невозможны», — говорит Гош. «Мы верим, что IDeAS Pro-ML, основанный на искусственном интеллекте и машинном обучении, позволит нам освободиться от традиционных ограничений дизайна и позволит нам создавать более оптимальные проекты за значительно меньшее время по сравнению с текущим состоянием искусства».
«Мы верим, что IDeAS Pro-ML, основанный на искусственном интеллекте и машинном обучении, позволит нам освободиться от традиционных ограничений дизайна и позволит нам создавать более оптимальные проекты за значительно меньшее время по сравнению с текущим состоянием искусства».
На фото модель вычислительной гидродинамики (CFD), предсказывающая траекторию потока и результирующие потери через ступицу лопатки газовой турбины. Показатели конструкции и производительности, такие как аэродинамические потери для турбины, будут оцениваться системой обратного проектирования с поддержкой искусственного интеллекта (ИИ) и машинного обучения (МО), разрабатываемой исследователями GE в рамках их проекта ARPA-E DIFFERENTIATE.
Гош добавил: «Одной из главных причин, по которой GE Gas Power установила мировые рекорды эффективности газовых турбин с комбинированным циклом (ПГУ), является разработка более эффективных аэродинамических деталей и компонентов. Благодаря интеграции новых цифровых решений на основе ИИ, таких как наша инвертируемая нейронная сеть, поддерживаемая программой ARPA-E DIFFERENTIATE, мы будем на пути к достижению эффективности 65% и выше».
Газотурбинная технология GE HA, которая включает в себя некоторые из самых передовых деталей и компонентов, помогла установить два мировых рекорда — один для питания самой эффективной в мире электростанции с комбинированным циклом, основанный на достижении полного КПД 63,08% в Chubu Electric. Nishi-Nagoya Power Plant Block-1 в Японии и еще один за помощь электростанции EDF Bouchain в достижении чистой эффективности комбинированного цикла 62,22% во Франции.
Вместе с командами GE Research и Gas Power группа исследователей из Университета Нотр-Дам под руководством профессора Николаса Забараса поделится своим более чем 30-летним опытом решения сложных обратных/проектных задач. Новаторская работа профессора Забараса в области методов регуляризации, многомерных байесовских обратных методов, моделей гауссовских процессов для инверсии и, совсем недавно, интеграции задач глубокого обучения и инверсии еще больше ускорит изучение этого проекта.
Конечной целью двухлетнего проекта является создание обратного процесса проектирования для оптимизации конструкции компонента лопатки газовой турбины и сокращения времени цикла проектирования. В будущем эта структура будет также распространена на другие приложения, такие как авиационные газотурбинные двигатели, авиационные двигатели, ветряные турбины и гидротурбины.
В будущем эта структура будет также распространена на другие приложения, такие как авиационные газотурбинные двигатели, авиационные двигатели, ветряные турбины и гидротурбины.
О GE Research
GE Research — центр инноваций GE, где исследования встречаются с реальностью. Мы — команда ученых, инженеров и маркетологов мирового класса, работающих на стыке физики и рынков, физических и цифровых технологий, а также в широком спектре отраслей, чтобы предоставлять нашим клиентам инновации и возможности, которые изменят мир. Чтобы узнать больше, посетите наш веб-сайт по адресу https://www.ge.com/research/.
«Это существенно изменит парадигму проектирования газовых турбин, позволив нам исследовать и открывать новые кривые обучения, которые ранее были невозможны. Мы верим, что IDeAS Pro-ML, основанный на искусственном интеллекте и машинном обучении, позволит нам освободиться от традиционных ограничений проектирования и позволит нам создавать более оптимальные проекты за значительно меньшее время по сравнению с текущим состоянием дел». — Саян Гош, ведущий инженер вероятностного проектирования и руководитель проекта
— Саян Гош, ведущий инженер вероятностного проектирования и руководитель проекта
Загрузка мультимедиа
GE Research’s Niskayuna Facility
Download
Лаборатория Edge
Скачать
Гигантский туннельный робот, похожий на дождевого червя, созданный GE
Аддитивные технологии
Скачать
Предприятие GE Research в Нискяуне
Загрузка
Мы здесь, чтобы решить ваши самые сложные проблемы.
Работать с нами
Помощь техническому персоналу с нейросимволическим ИИ
Эта статья является частью исследовательского блога Bosch
Откройте для себя всю серию
Нейросимволические методы искусственного интеллекта могут объединять данные, сгенерированные машиной, и технические ноу-хау человека в интегрированный свод знаний, в конечном итоге генерируя рекомендации, которые специалисты в данной области могут использовать в своей работе. рабочее место.
рабочее место.
За продуктами и услугами, составляющими вселенную Bosch, стоит кропотливая работа профильных экспертов, исследователей и инженеров. Вдобавок к этому, технологии на основе ИИ становятся все более актуальными, когда речь идет о помощи нашим узкоспециализированным сотрудникам в принятии технических решений, что отражает общую тенденцию в отрасли к внедрению ИИ на разных этапах жизненного цикла продукта — от проектирования до коммерциализации.
В этом контексте крайне важно иметь структуру, гарантирующую, что поддержка принятия решений на основе ИИ может развиваться эффективно и действенно, и в которой человеческий технический опыт, как правило, накопленный за годы практического опыта и постоянного обучения, может быть последовательно объединен. и используются вместе с вычислительными алгоритмами. Несоблюдение этого требования может привести к подрыву доверия к ИИ, что противоречит одной из основных целей этой технологии, то есть способствовать сотрудничеству человека и машины. Интеграция между символическими и субсимволическими методами ИИ, которую мы называем Нейросимволический ИИ может взять на себя роль вышеупомянутой структуры: Нейросимволический ИИ может собирать экспертные ноу-хау, комбинируя их с семантически структурированными данными, в конечном итоге превращая этот корпус знаний в действенные рекомендации, которые могут использовать эксперты. следить за своевременным принятием решений. Эта трансформация происходит посредством нейросимволических рассуждений , возникающих в результате взаимодействия между выводами, основанными на правилах , когнитивно адекватным способом формализации экспертного ноу-хау, и машинное обучение , которое можно использовать для быстрого получения информации из больших объемов данных — процесс, который в противном случае отнимал бы много времени и требовал чрезвычайных ручных усилий (например, поиск ошибок, повторяющихся шаблонов и т. д.).
Интеграция между символическими и субсимволическими методами ИИ, которую мы называем Нейросимволический ИИ может взять на себя роль вышеупомянутой структуры: Нейросимволический ИИ может собирать экспертные ноу-хау, комбинируя их с семантически структурированными данными, в конечном итоге превращая этот корпус знаний в действенные рекомендации, которые могут использовать эксперты. следить за своевременным принятием решений. Эта трансформация происходит посредством нейросимволических рассуждений , возникающих в результате взаимодействия между выводами, основанными на правилах , когнитивно адекватным способом формализации экспертного ноу-хау, и машинное обучение , которое можно использовать для быстрого получения информации из больших объемов данных — процесс, который в противном случае отнимал бы много времени и требовал чрезвычайных ручных усилий (например, поиск ошибок, повторяющихся шаблонов и т. д.).
Оценка осуществимости проекта (PFA) в ECU (двигатель автомобиля) Калибровка систем трансмиссии может быть определена как всесторонний процесс установления того, может ли автомобиль достичь целевого стандарта выбросов.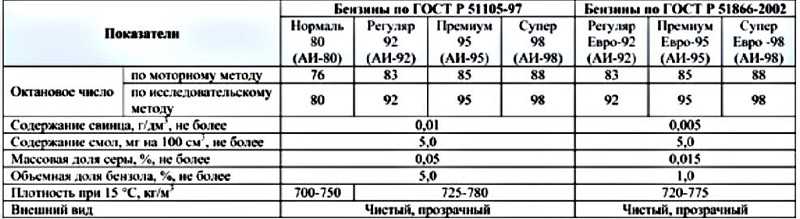 PFA обычно охватывает обычные двигатели внутреннего сгорания (бензиновые, дизельные или альтернативные виды топлива), а также конфигурации гибридных силовых агрегатов. Этот процесс выполняется экспертами, которым поручено собирать и анализировать информацию из различных источников, включая измерения выбросов, данные о транспортных средствах и т. д., а также оценивать двигатели на основе различных требований и функций. Эксперты по калибровке выбросов должны понимать корреляции и взаимозависимости в обширных массивах разнородных данных, что делает PFA сложной задачей. Соответственно, мы разработали решение для поддержки принятия решений на основе нейросимволического ИИ, которое включает в себя вычислительные правила, которые моделируют, как эксперты по калибровке выбросов решают, выполним проект или нет, и алгоритмы машинного обучения, которые используются для кластеризации проектов на основе признаков подобия и для прогнозирования пропущенных измерений. Наш подход обеспечивает согласованное и компактное семантическое представление данных в масштабе с помощью конвейера интеграции на основе графа знаний.
PFA обычно охватывает обычные двигатели внутреннего сгорания (бензиновые, дизельные или альтернативные виды топлива), а также конфигурации гибридных силовых агрегатов. Этот процесс выполняется экспертами, которым поручено собирать и анализировать информацию из различных источников, включая измерения выбросов, данные о транспортных средствах и т. д., а также оценивать двигатели на основе различных требований и функций. Эксперты по калибровке выбросов должны понимать корреляции и взаимозависимости в обширных массивах разнородных данных, что делает PFA сложной задачей. Соответственно, мы разработали решение для поддержки принятия решений на основе нейросимволического ИИ, которое включает в себя вычислительные правила, которые моделируют, как эксперты по калибровке выбросов решают, выполним проект или нет, и алгоритмы машинного обучения, которые используются для кластеризации проектов на основе признаков подобия и для прогнозирования пропущенных измерений. Наш подход обеспечивает согласованное и компактное семантическое представление данных в масштабе с помощью конвейера интеграции на основе графа знаний. Интеграция рассуждений на основе правил и машинного обучения регулируется различными факторами, среди которых 9.0346 Полнота информации имеет ключевое значение: например, когда оценивается новый двигатель, но данные о выбросах определенных загрязняющих веществ недоступны, система сначала заполнит пробелы, предсказав отсутствующие значения измерений, а затем применит контекстно-зависимые правила, смоделированные на основе данных эксперта. эвристическая техника. Важно отметить, что эта система поддержки принятия решений на основе нейросимволического ИИ является динамичной: ее можно переобучить для учета новых данных и правил, где первые становятся естественным образом доступными по мере развития технологий сгорания и автомобилей, а вторые отражают необходимость для экспертов обновлять свои правила по мере введения новых стандартов и, следовательно, новой государственной политики.
Интеграция рассуждений на основе правил и машинного обучения регулируется различными факторами, среди которых 9.0346 Полнота информации имеет ключевое значение: например, когда оценивается новый двигатель, но данные о выбросах определенных загрязняющих веществ недоступны, система сначала заполнит пробелы, предсказав отсутствующие значения измерений, а затем применит контекстно-зависимые правила, смоделированные на основе данных эксперта. эвристическая техника. Важно отметить, что эта система поддержки принятия решений на основе нейросимволического ИИ является динамичной: ее можно переобучить для учета новых данных и правил, где первые становятся естественным образом доступными по мере развития технологий сгорания и автомобилей, а вторые отражают необходимость для экспертов обновлять свои правила по мере введения новых стандартов и, следовательно, новой государственной политики.
В соответствии с этическим кодексом Bosch для искусственного интеллекта, наше нейросимволическое решение искусственного интеллекта для PFA стремится быть надежным за счет использования больших хранилищ данных, экспертных правил и хорошо зарекомендовавших себя методов машинного обучения; Надежный , путем тестирования гибридных рассуждений в конфигурациях ECU с историческими записями в качестве истинной истины; и объяснимых , выявив методы рассуждений и детали для каждой рекомендации.