Расшифровка ai: UAI, BB, HB, AI — расшифровка сокращений типов питания в отелях
простыми словами о технологиях / Хабр
Представляем исчерпывающую шпаргалку, где мы простыми словами рассказываем, из чего «делают» искусственный интеллект и как это все работает.
Разграничение понятий в области искусственного интеллекта и анализа данных.
Artificial Intelligence — AI (Искусственный Интеллект)
В глобальном общечеловеческом смысле ИИ — термин максимально широкий. Он включает в себя как научные теории, так и конкретные технологические практики по созданию программ, приближенных к интеллекту человека.
Раздел AI, активно применяющийся на практике. Сегодня, когда речь заходит об использовании AI в бизнесе или на производстве, чаще всего имеется в виду именно Machine Learning.
ML-алгоритмы, как правило, работают по принципу обучающейся математической модели, которая производит анализ на основе большого объема данных, при этом выводы делаются без следования жестко заданным правилам.
Наиболее частый тип задач в машинном обучении — это обучение с учителем. Для решения такого рода задач используется обучение на массиве данных, по которым ответ заранее известен (см.ниже).
Наука и практика анализа больших объемов данных с помощью всевозможных математических методов, в том числе машинного обучения, а также решение смежных задач, связанных со сбором, хранением и обработкой массивов данных.
Data Scientists — специалисты по работе с данными, в частности, проводящие анализ при помощи machine learning.
Рассмотрим работу ML на примере задачи банковского скоринга. Банк располагает данными о существующих клиентах. Ему известно, есть ли у кого-то просроченные платежи по кредитам. Задача — определить, будет ли новый потенциальный клиент вовремя вносить платежи. По каждому клиенту банк обладает совокупностью определенных черт/признаков: пол, возраст, ежемесячный доход, профессия, место проживания, образование и пр. В числе характеристик могут быть и слабоструктурированные параметры, такие как данные из соцсетей или история покупок. Кроме того, данные можно обогатить информацией из внешних источников: курсы валют, данные кредитных бюро и т. п.
В числе характеристик могут быть и слабоструктурированные параметры, такие как данные из соцсетей или история покупок. Кроме того, данные можно обогатить информацией из внешних источников: курсы валют, данные кредитных бюро и т. п.
Машина видит любого клиента как совокупность признаков: . Где, например, — возраст, — доход, а — количество фотографий дорогих покупок в месяц (на практике в рамках подобной задачи Data Scientist работает с более чем сотней признаков). Каждому клиенту соответствует еще одна переменная — с двумя возможными исходами: 1 (есть просроченные платежи) или 0 (нет просроченных платежей).
Совокупность всех данных и — есть Data Set. Используя эти данные, Data Scientist создает модель , подбирая и дорабатывая алгоритм машинного обучения.
В этом случае модель анализа выглядит так:
Алгоритмы машинного обучения подразумевают поэтапное приближение ответов модели к истинным ответам (которые в обучающем Data Set известны заранее). Это и есть обучение с учителем на определенной выборке.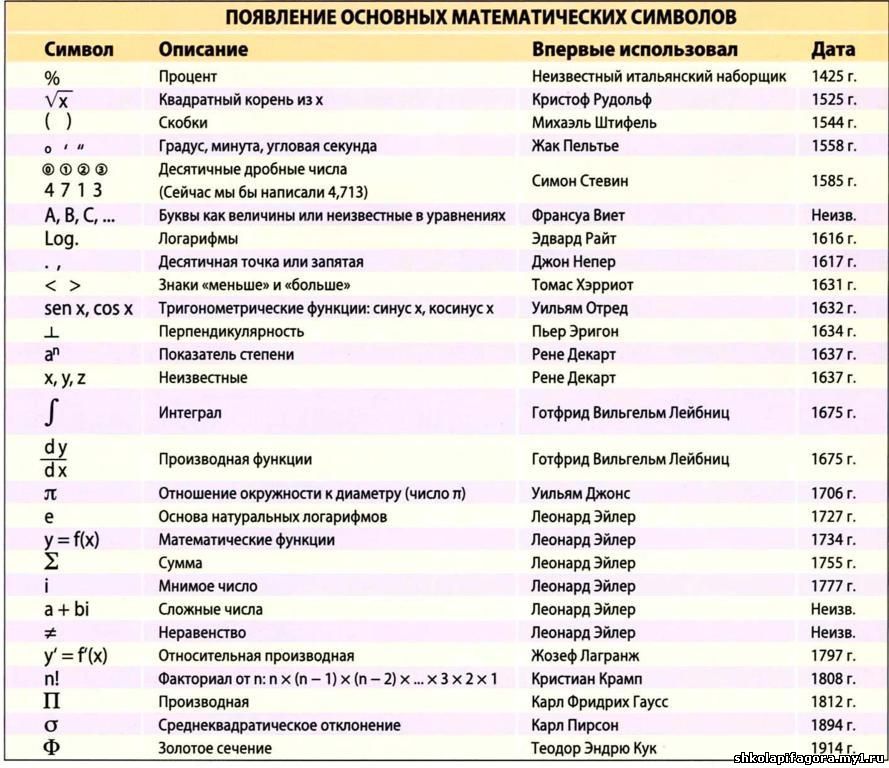
На практике чаще всего машина обучается лишь на части массива (80 %), применяя остаток (20 %) для проверки правильности выбранного алгоритма. Например, система может обучаться на массиве, из которого исключены данные пары регионов, на которых сверяется точность модели после.
Теперь, когда в банк приходит новый клиент, по которому еще не известен банку, система подскажет надежность плательщика, основываясь на известных о нем данных .
Однако, обучение с учителем — не единственный класс задач, которые способна решать ML.
Другой спектр задач — кластеризация, способная разделять объекты по признакам, например, выявлять разные категории клиентов для составления им индивидуальных предложений.
Также с помощью ML-алгоритмов решаются такие задачи, как моделирование общения специалиста поддержки или создание художественных произведений, неотличимых от сотворенных человеком (например, нейросети рисуют картины).
Новый и популярный класс задач — обучение с подкреплением, которое проходит в ограниченной среде, оценивающей действия агентов (например, с помощью такого алгоритма удалось создать AlphaGo, победившую человека в Го).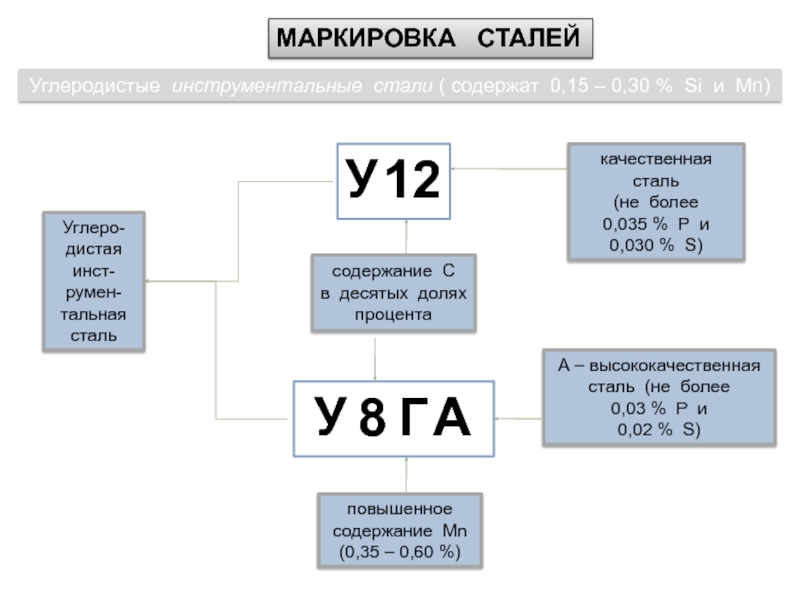
Нейронная сеть
Один из методов Machine Learning. Алгоритм, вдохновленный структурой человеческого мозга, в основе которой лежат нейроны и связи между ними. В процессе обучения происходит подстройка связей между нейронами таким образом, чтобы минимизировать ошибки всей сети.
Особенностью нейронных сетей является наличие архитектур, подходящих практически под любой формат данных: сверточные нейросети для анализа картинок, рекуррентные нейросети для анализа текстов и последовательностей, автоэнкодеры для сжатия данных, генеративные нейросети для создания новых объектов и т. д.
В то же время практически все нейросети обладают существенным ограничением — для их обучения нужно большое количество данных (на порядки большее, чем число связей между нейронами в этой сети). Благодаря тому, что в последнее время объемы готовых для анализа данных значительно выросли, растет и сфера применения. С помощью нейросетей сегодня, например, решаются задачи распознавания изображений, такие как определение по видео возраста и пола человека, или наличие каски на рабочем.
Интерпретация результата
Раздел Data Science, позволяющий понять причины выбора ML-моделью того или иного решения.
Существует два основных направления исследований:
- Изучение модели как «черного ящика». Анализируя загруженные в него примеры, алгоритм сравнивает признаки этих примеров и выводы алгоритма, делая выводы о приоритете каких-либо из них. В случае с нейросетями обычно применяют именно черный ящик.
- Изучение свойств самой модели. Изучение признаков, которые использует модель, для определения степени их важности. Чаще всего применяется к алгоритмам, основанным на методе решающих деревьев.
Например, при прогнозировании брака на производстве признаки объектов — это данные настроек станков, химический состав сырья, показатели датчиков, видео с конвейера и т. д. А ответы – это ответы на вопрос, будет ли брак или нет.
Естественно, производство интересует не только прогноз самого брака, но и интерпретация результата, т. е. причины брака для их последующего устранения. Это может быть долгое отсутствие тех.обслуживания станка, качество сырья, или просто аномальные показания некоторых датчиков, на которые технологу стоит обратить внимание.
е. причины брака для их последующего устранения. Это может быть долгое отсутствие тех.обслуживания станка, качество сырья, или просто аномальные показания некоторых датчиков, на которые технологу стоит обратить внимание.
Потому в рамках проекта прогноза брака на производстве должна быть не просто создана ML-модель, но и проделана работа по её интерпретации, т. е. по выявлению факторов, влияющих на брак.
Когда есть большой набор статистических данных, но найти в них зависимости экспертными или классическими математическими методами невозможно или очень трудоемко. Так, если на входе есть более тысячи параметров (среди которых как числовые, так и текстовые, а также видео, аудио и картинки), то найти зависимость результата от них без машины невозможно.
Например, на химическую реакцию кроме самих вступающих во взаимодействие веществ влияет множество параметров: температура, влажность, материал емкости, в которой она происходит, и т. д. Химику сложно учесть все эти признаки, чтобы точно рассчитать время реакции. Скорее всего, он учтет несколько ключевых параметров и будет основываться на своем опыте. В то же время на основании данных предыдущих реакций машинное обучение сможет учесть все признаки и дать более точный прогноз.
д. Химику сложно учесть все эти признаки, чтобы точно рассчитать время реакции. Скорее всего, он учтет несколько ключевых параметров и будет основываться на своем опыте. В то же время на основании данных предыдущих реакций машинное обучение сможет учесть все признаки и дать более точный прогноз.
Как связаны Big Data и машинное обучение?
Для построения моделей машинного обучения требуются в разных случаях числовые, текстовые, фото, видео, аудио и иные данные. Для того чтобы эту информацию хранить и анализировать существует целая область технологий — Big Data. Для оптимального накопления данных и их анализа создают «озера данных» (Data Lake) — специальные распределенные хранилища для больших объемов слабоструктированной информации на базе технологий Big Data.
Цифровой двойник как электронный паспорт
Цифровой двойник — виртуальная копия реального материального объекта, процесса или организации, которая позволяет моделировать поведение изучаемого объекта/процесса. Например, можно предварительно увидеть результаты изменения химического состава на производстве после изменений настроек производственных линий, изменений продаж после проведения рекламной кампании с теми или иными характеристиками и т. д. При этом прогнозы строятся цифровым двойником на основе накопленных данных, а сценарии и будущие ситуации моделируются в том числе методами машинного обучения.
Например, можно предварительно увидеть результаты изменения химического состава на производстве после изменений настроек производственных линий, изменений продаж после проведения рекламной кампании с теми или иными характеристиками и т. д. При этом прогнозы строятся цифровым двойником на основе накопленных данных, а сценарии и будущие ситуации моделируются в том числе методами машинного обучения.
Data Scientiest’ы! Именно они создают алгоритм прогноза: изучают имеющиеся данные, выдвигают гипотезы, строят модели на основе Data Set. Они должны обладать тремя основными группами навыков: IT-грамотностью, математическими и статистическими знаниями и содержательным опытом в конкретной области.
Машинное обучение стоит на трех китах
Получение данных
Могут быть использованы данные из смежных систем: график работ, план продаж. Данные могут быть также обогащены внешними источниками: курсы валют, погода, календарь праздников и т.
Построение признаков
Проводится вместе с экспертами из необходимой области. Это помогает вычислить данные, которые хорошо подходят для прогнозирования целей: статистика и изменение количества продаж за последний месяц для прогноза рынка.
Модель машинного обучения
Метод решения поставленной бизнес-задачи выбирает data scientist самостоятельно на основании своего опыта и возможностей различных моделей. Под каждую конкретную задачу необходимо подобрать отдельный алгоритм. От выбранного метода напрямую зависят скорость и точность результата обработки исходных данных.
Процесс создания ML-модели.
1. Всё начинается с гипотезы
Гипотеза рождается при анализе проблемного процесса, опыта сотрудников или при свежем взгляде на производство.
В таком процессе применение машинного обучения позволяет использовать существенно больше информации при принятии решений, поэтому, возможно, удается достичь существенно лучших результатов. Плюс ко всему, автоматизация процессов с помощью ML и снижение зависимости от конкретного человека существенно минимизируют человеческий фактор (болезнь, низкая концентрация и т. д.).
2. Оценка гипотезы
На основании сформулированной гипотезы выбираются данные, необходимые для разработки модели машинного обучения. Осуществляется поиск соответствующих данных и оценка их пригодности для встраивания модели в текущие процессы, определяется, кто будет ее пользователями и за счет чего достигается эффект. При необходимости вносятся организационные и любые другие изменения.
3. Расчет экономического эффекта и возврата инвестиций (ROI)
Оценка экономического эффекта внедряемого решения производится специалистами совместно с соответствующими департаментами: эффективности, финансов и т. д. На данном этапе необходимо понять, что именно является метрикой (количество верно выявленных клиентов / увеличение выпуска продукции / экономия расходных материалов и т. п.) и четко сформулировать измеряемую цель.
4. Математическая постановка задачи
После понимания бизнес-результата его необходимо переложить в математическую плоскость — определить метрики измерений и ограничения, которые нельзя нарушать. Данные этапы data
scientist выполняет совместно с бизнес-заказчиком.
5. Сбор и анализ данных
Необходимо собрать данные в одном месте, проанализировать их, рассматривая различные статистики, понять структуру и скрытые взаимосвязи этих данных для формирования признаков.
6. Создание прототипа
Является, по сути, проверкой гипотезы. Это возможность построения модели на текущих данных и первичной проверки результатов ее работы. Обычно прототип делается на имеющихся данных без разработки интеграций и работы с потоком в реальном времени.
Создание прототипа — быстрый и недорогой способ проверить, решаема ли задача. Это весьма полезно в том случае, когда невозможно заранее понять, получится ли достичь нужного экономического эффекта. К тому же процесс создания прототипа позволяет лучше оценить объем и подробности проекта по внедрению решения, подготовить экономическое обоснование такого внедрения.
DevOps и DataOps
В процессе эксплуатации может появится новый тип данных (например, появится ещё один датчик на станке или же на складе появится новый тип товаров) тогда модель нужно дообучить. DevOps и DataOps — методологии, которые помогают настроить совместную работу и сквозные процессы между командами Data Science, инженерами по подготовке данных, службами разработки и эксплуатации ИТ-систем, и помогают сделать такие дополнения частью текущего процесса быстро, без ошибок и без решения каждый раз уникальных проблем.

7. Создание решения
В тот момент, когда результаты работы прототипа демонстрируют уверенное достижение показателей, создается полноценное решение, где модель машинного обучения является лишь составляющей изучаемых процессов. Далее производится интеграция, установка необходимого оборудования, обучение персонала, изменение процессов принятия решений и т. Д.
8. Опытная и промышленная эксплуатация
Во время опытной эксплуатации система работает в режиме советов, в то время как специалист еще повторяет привычные действия, каждый раз давая обратную связь о необходимых улучшениях системы и увеличении точности прогнозов.
Финальная часть — промышленная эксплуатация, когда налаженные процессы переходят на полностью автоматическое обслуживание.
Шпаргалку можно скачать по ссылке.
Завтра на форуме по системам искусственного интеллекта RAIF 2019 в 09:30 — 10:45 состоится панельная дискуссия: «AI для людей: разбираемся простыми словами».
В этой секции в формате дебатов спикеры объяснят простыми словами на жизненных примерах сложные технологии. А также подискутируют на следующие темы:
- В чем разница между Artificial Intelligence, Machine Learning и Data Science?
- Как работает машинное обучение?
- Как работают нейронные сети?
- Что нужно для качественного машинного обучения?
- Что такое разметка, маркировка данных?
- Что такое цифровой двойник и как работать с виртуальными копиями реальных материальных объектов?
- В чем суть гипотезы? Как пройти путь от её постановки до оценки и интерпретации результата?
В дискуссии принимают участие:
Николай Марин, директор по технологиям, IBM в России и СНГ
Алексей Натекин, основатель, Open Data Science x Data Souls
Алексей Хахунов, технический директор, Dbrain
Евгений Колесников, директор Центра машинного обучения, Инфосистемы Джет
Павел Доронин, CEO, AI Today
Дискуссия будет доступна на канале YouTube «Инфосистемы Джет» в конце октября.
категории системы питания в гостиницах OB, BB, HB, FB, AI, UAI
Путешествие путешествием, а завтрак должен быть по расписанию. Так считают туристы. Бронируя отель, они обращают внимание на графу «Питание». Непонятные аббревиатуры напротив пункта с питанием смущают многих. Раскрывая «секреты», в данном материале даем подробную расшифровку типов питания в отелях: RO, BB, HB, BF, AI, UAI. Английские буквосочетания приобретают смысл, выбор услуг становится проще после подробного знакомства с непонятными символами.
Предложения по питанию от гостиниц: что обозначают буквенные сокращения
Питание – важная часть человеческой жизни, от которого зависит энергия, настроение, работоспособность, желание радоваться, отдыхать. Предопределяя вопросы о системе питания в отелях, их обозначениях ирасшифровках, знакомим с международными гостиничными стандартными аббревиатурами. Основные обозначения, которыми пользуются гостиничные комплексы всего мира, следующие:
- UAI («ультра все включено»).
 Это максимальный набор услуг. Тут есть все – от круглосуточного питания с напитками (алкогольными, безалкогольными отечественного и импортного производителя) до бассейнов-саун-ночных клубов и др. Соответственно стоимость такого проживания исчисляется многочисленными нулями. Рассчитаны подобные блага на богатых отдыхающих, не желающих думать о приготовлении еды и проведении досуга.
Это максимальный набор услуг. Тут есть все – от круглосуточного питания с напитками (алкогольными, безалкогольными отечественного и импортного производителя) до бассейнов-саун-ночных клубов и др. Соответственно стоимость такого проживания исчисляется многочисленными нулями. Рассчитаны подобные блага на богатых отдыхающих, не желающих думать о приготовлении еды и проведении досуга. - AI, ALL INC (all inclusive) («все включено»). Удобно тем, что не ограничена трапеза временем приема пищи: отдыхающий может в течение дня, утра, вечера утолять аппетит вкусными блюдами и десертами. Данные типы питания в отелях включают 5-разовую трапезу без ограничений. За алкогольные напитки отечественного производителя платить не приходится. Возможен второй вариант отельной трапезы – трехразовой, с бесплатными напитками на протяжении дня.
- FB, FB+ (полный пансион). Трапеза в этом случае трехразовая со всевозможными вкусностями. В варианте с плюсом предполагаются бесплатные крепкие и полукрепкие алкогольные напитки отечественного производителя.
- HB, HB+ (halfboard) – полупансионное размещение. Такой вид проживания в отельном комплексе предполагает питание сытное 2-разовое. Стандартно предлагают сытные завтраки-ужины. Иногда гостям дают возможность выбирать, когда питаться второй раз – обеды или ужины. За напитки алкогольные придется платить отдельно (HB) или не платить за напитки отечественного производителя (HB+), безалкогольные – бесплатные.
- BB («кровать-завтрак»). Вариации завтраков, в зависимости от уровня гостиничного комплекса. Дешевые – легкие Breakfast Continental (свежая выпечка, масло-джем-кофе (чай)). Дорогие и сытные — americanbulet (после такого завтрака можно спокойно не обедать: горячие блюда, сырно-колбасные нарезки, напитки горячие, фруктовые). Средний по стоимости и по сытости – вreakfast English.
- RR, RO, AO, BO, OB («только комната, размещение, кровать» — room only, Only Bed и т.д.). Туристы, которые не намерены проводить время на территории гостиничного комплекса, в трапезе не нуждаются. Выбор дешевого вида поселения, обеспечивающий место проживания, не предполагает питания, даже легкого завтрака.
 Это максимальный набор услуг. Тут есть все – от круглосуточного питания с напитками (алкогольными, безалкогольными отечественного и импортного производителя) до бассейнов-саун-ночных клубов и др. Соответственно стоимость такого проживания исчисляется многочисленными нулями. Рассчитаны подобные блага на богатых отдыхающих, не желающих думать о приготовлении еды и проведении досуга.
Это максимальный набор услуг. Тут есть все – от круглосуточного питания с напитками (алкогольными, безалкогольными отечественного и импортного производителя) до бассейнов-саун-ночных клубов и др. Соответственно стоимость такого проживания исчисляется многочисленными нулями. Рассчитаны подобные блага на богатых отдыхающих, не желающих думать о приготовлении еды и проведении досуга.
 Выбор дешевого вида поселения, обеспечивающий место проживания, не предполагает питания, даже легкого завтрака.
Выбор дешевого вида поселения, обеспечивающий место проживания, не предполагает питания, даже легкого завтрака.Все заведения, размещающие путешественников, используют стандартные вышеперечисленные обозначения питания в отелях. Это первые буквы английских слов. Зная расшифровку и перевод, возможно легко сориентироваться в количестве предоставляемых услуг, понять, стоит ли бронировать проживание в отеле.
О типах питания и историческом прошлом некоторых слов
С буквенными обозначениями разобрались, осталось понять стандартные системы питания в отелях с расшифровками смысла слов и словосочетаний.
Слова «пансион», «полупансион» пришли из прошлого, в дореволюционные времена обозначали небольшую гостиницу с полным или частичным содержанием постояльцев. Сегодня это стандартный комплекс услуг, предлагаемый отелями проживающим. Эти виды питания в отелях означают соответственно полноценную трапезу — двухразовую (завтрак, ужин), трехразовую (завтрак, обед, ужин). Отдельно приходится платить за напитки.
Отдельно приходится платить за напитки.
Восполнив пробелы в знаниях о том, как обозначается питание в отелях, легко понять, что представляет собой всеобъемлющая услуга «все включено». В нее входят обязательные сытные утренние трапезы с неограниченным количеством напитков, барбекю, закуски; комплекс услуг, предлагаемый гостиницей.
Та же услуга с приставкой «ультра» увеличивает количества гостиничных благ, которыми может пользоваться гость, помимо завтраков-обедов-ужинов. Их перечень отельный комплекс определяет индивидуально – от массажей и саун до бассейна и ночного клуба. Все для туристов, которые желают отдохнуть по полной.
С понятием «шведский стол» хорошо знакомы путешествующие за границей. Удобный вид самообслуживания во время трапезы, когда из множества предложенных яств возможно выбирать понравившиеся блюда по типам – салат, первые блюда, гарнир, мясо, рыба, десерт, фрукты, напитки (соки, кофе, чай, молоко, какао). Ограничений количества пищи нет, запрещается выносить. Для еды подготовлена специальная посуда и столовые приборы.
Для еды подготовлена специальная посуда и столовые приборы.
Для туристов расшифровка питания в отелях по буквам – полезная информация. Во-первых, это стандартные обозначения для гостиничных комплексов во всем мире. Во-вторых, бронируя номер, знаешь, чего ожидать и избавлен от неприятных неожиданностей. В-третьих, зная нюансы, можно сэкономить.
Отель «Ключевой Элемент» предлагает выгодные гибкие тарифы на проживание в комфортабельных номерах, вкусные сытные завтраки с доставкой в номер. Меню разнообразим ежедневно.
Каждый выбирает по себе тип питания в гостинице – в зависимости от характера, привычек, предпочтений в еде, стиля жизни. Желаем правильных выборов, вкусной еды, удачных путешествий!
Типы питания в отелях — расшифровка RO, BB, HB, BF, AI, UAI
«А ты путешественник, что ли? А ну-ка, скажи что-нибудь по-гостиничному». Отельный язык напоминает позывные секретных агентов из шпионских саг: куча сокращений и аббревиатур, в которых скрывается сакральный смысл — в каких условиях ты проведёшь свой долгожданный отпуск. Чтобы не провалить операцию «Отдых», лови расшифровки типов питания.
Чтобы не провалить операцию «Отдых», лови расшифровки типов питания.
Содержание
- RO
- BB
- HB
- FB
- HB+ и FB+
- Al
- UAI
RO
RO означает «room only». Расшифровка исчерпывающая: ты бронируешь только номер, питание в стоимость проживания не входит. Этот тип питания распространён в отелях, хостелах и на виллах. Такой вариант идеально подойдёт тем, кто не хочет привязываться к расписанию завтраков-обедов-ужинов. Ты можешь как угодно планировать свой день в поездке, не боясь пропустить уже оплаченную трапезу. А еду приготовишь на кухне или отведаешь все прелести местной кухни в ресторанах и кафе.
BB
ВВ (он же «bed & breakfast» — постель и завтрак) — самый частый тип питания в отелях. В стоимость номера будет включён завтрак. Есть два распространённых формата — «шведский стол» и континентальный завтрак.
Фото: mikecphoto/Shutterstock
- «Шведский стол» — обширная фуршетная линия с закусками, горячими блюдами, фруктами и десертами. Неограниченное количество подходов и порции любых размеров.
- Континентальный завтрак — порционное питание. Чаще всего состоит из яичницы, бекона или сосисок, овощей, тостов, круассана и кофе.
 Неограниченное количество подходов и порции любых размеров.
Неограниченное количество подходов и порции любых размеров.ВВ идеально подойдёт для тех, кто не в духе по утрам: не нужно заморачиваться с готовкой или выбором кафе, всё сервируют и уберут, тебе остаётся только хорошо кушать (почти как у бабушки).
HB
Под аббревиатурой HB (он же «half board») скрывается полупансион — тип питания, в который входят завтрак и ужин. В завтраки, как правило, включены напитки (чай, кофе, сок, вода), а вот в ужины — нет. Напитки будут стоить в несколько раз дороже, нежели точно такие же в магазине. Однако такой тип питания очень удобен для семей с детьми и людей, соблюдающих режим питания. Об утренней и вечерней трапезе беспокоиться не придётся — всё будет строго по часам, а пообедать можно будет во время прогулки в городе.
FB
Аббревиатурой FB (Full Board) обозначается трёхразовое питание — завтрак, обед и ужин. Этот тип питания подойдёт тем, кому нужен размеренный санаторный отдых без лишних передвижений. Как и в HB, в Full Board напитки входят только в завтрак. На обед и на ужин они могут подаваться за отдельную плату.
Этот тип питания подойдёт тем, кому нужен размеренный санаторный отдых без лишних передвижений. Как и в HB, в Full Board напитки входят только в завтрак. На обед и на ужин они могут подаваться за отдельную плату.
HB+ и FB+
В некоторых отелях встречается разновидность полупансиона HB+ и полного пансиона FB+. В этих типах питания включены бесплатные напитки во время всех приёмов пищи. Ассортимент и количество на одного гостя зависят от отеля.
AI
С системой AI (All inclusive, или «всё включено») знакомы те, кто хоть раз бронировал отель в Турции. All inclusive включает трёхразовое питание, напитки и даже алкоголь местного производства. Такой тип питания предлагается в резорт-отелях, которые напоминают город в городе. У них есть собственная инфраструктура: бассейны, пляж, рестораны, бары и кафе на территории, фитнес-клубы, магазины и многое другое — словом, тут есть всё, чтобы вдоволь «потюленить» и лишний раз не выходить за пределы отеля. Такой тип питания подойдёт хронически усталым путешественникам, которым хочется устроить торжество лени, а также семьям с детьми, чтобы маленьким путешественникам в любой момент можно было чем-то подкрепиться.
UAI
UAI (Ultra All inclusive) представляет собой расширенный AI. Помимо трёхразового питания и местных напитков, ты сможешь отведать и напитки импортного производства, как алкогольные, так и без-.
Позывные получены. Мы за тебя спокойны, теперь точно не провалишь явку и выберешь отель с нужным типом питания. Мечтай, бронируй, отдыхай.
Подпишись на горячие новинки блога!
Подпишись на обновления блога, и мы откроем для тебя целый мир вдохновляющих путешествий, тревел-лайфхаков и небанальных направлений на все случаи и для любых компаний.
Посмотреть на эти чудесные письма
Электронная почта
Подписаться
Я согласен с «Политикой по обработке персональных данных».
Ошибка на сервере. Не удалось отправить ваши данные. Пожалуйста, попробуйте еще раз!
Спасибо
Мы уже отправили вам письмо. Проверьте, пожалуйста!
Проверьте, пожалуйста!
Направление
1 номер для
Взрослые 123456
Дети 01234
Готово
Искать авиабилеты на те же даты
Найти отели
Мария Макеева
Журналист, путешественник, люблю планировать и составлять инструкции. Исколесила всю Европу, большую часть Азии, не забывала и про Россию-матушку. Пожила в Таиланде, была на Ближнем Востоке. Привожу из поездок колокольчики, рецепты и местный фольклор.
Все записи автора
выпусков · Ciphey/Ciphey · GitHub
Добавьте больше методов расшифровки
#63 открыт 27 мая 2020 г. автором пчела-сан
Открытым
206.0.0 выпуск
#591
открыт 8 марта 2021 г. автором
пчела-сан
автором
пчела-сан
Открытым
4 Новый выпускЕсть вопрос по этому проекту? Зарегистрируйте бесплатную учетную запись GitHub, чтобы открыть задачу и связаться с ее сопровождающими и сообществом.
Зарегистрируйтесь на GitHub
Нажимая «Зарегистрироваться на GitHub», вы соглашаетесь с нашими условиями обслуживания и Заявление о конфиденциальности. Время от времени мы будем отправлять вам электронные письма, связанные с учетной записью.
Уже на GitHub? Войти на ваш счет
Ветвящиеся декодеры/контроллеры. улучшение
Новая функция или запрос#751 открыт 11 августа 2022 г. автором Sertingolix
Взлом шифра AI улучшение
Новая функция или запрос #750
открыт 13 июля 2022 г. автором
MrBrain295
автором
MrBrain295
установить при ошибке докера ошибка
Что-то не работает#749 открыт 9 июля 2022 г. автором 866666
как указать аргументы кода, если я знаю, что результатом являются все числа? ошибка
Что-то не работает#745 открыл
28 июня 2022 г.автором WatsonLiang22
1 задание выполнено
ciphey Думает… неизменно! ошибка
Что-то не работает#743 открыт 22 июня 2022 г. автором lijiachang
Обновление документации для Wordlist улучшение
Новая функция или запрос#742 открыт 14 июня 2022 г. автором gleporeNARA
Добавить взломщик Enigma и кодировщик/декодер улучшение
Новая функция или запрос #724
открыт 7 февраля 2022 г. автором
eabase
автором
eabase
«индекс строки вне допустимого диапазона» для флага -t ошибка
Что-то не работает#713 открыт 21 нояб. 2021 г. автором LPoeppel
[Предложение] Умный поиск улучшение
Новая функция или запрос#659 открыт 7 июня 2021 г. автором bee-san
Написать больше тестов ошибка
Что-то не работает#651 открыт 24 мая 2021 г. автором bee-san
Заменить крекер Цезарь ошибка
Что-то не работает#642 открыт 22 мая 2021 г. автором bee-san
Заменить взломщик Vigenere ошибка
Что-то не работает#641 открыт 22 мая 2021 г. автором bee-san
Переписать нашу печать в отдельный модуль ошибка
Что-то не работает #640
открыт 22 мая 2021 г. автором
пчела-сан
автором
пчела-сан
Поощряйте людей, использующих средство проверки регулярных выражений, сообщать о том, что ошибка
Что-то не работает#636 открыт 21 мая 2021 г. bee-san
Использовать только один объект rich.console
#635 открыт 21 мая 2021 г. bee-san
Сделать формат возврата API + проверки пройдены улучшение
Новая функция или запрос#631 открыт 21 мая 2021 г. bee-san
Добавить семейство проектов в README техническое обслуживание
Что-то, что не влияет на пользователя напрямую#625 открыт 20 мая 2021 г. bee-san
Реализовать поиск по хешу для взлома хэша улучшение
Новая функция или запросНовый декодер
Для новых декодеров/расшифровщиков! #620
открыт 20 мая 2021 г. bee-san
bee-san
Ciphey не может расшифровать шифр Цезаря + Base64 ошибка
Что-то не работает#606 открыт 25 апр. 2021 г. автором jmlgomez73
Невозможно прервать Ctrl+C ошибка
Что-то не работает#605 открыл
12 апреля 2021 г.автором FalcoGer
1 задание выполнено
Распечатать все расшифровки, даже если это не открытый текст улучшение
Новая функция или запрос#604 открыт 10 апр. 2021 г. автором bee-san
[Ошибка] Невозможно декодировать строку, закодированную rot47 ошибка
Что-то не работает#601 открыл
10 апреля 2021 г.
автором Анон-эксплуататор
1 задание выполнено
Версия 6.0.0 техническое обслуживание
Что-то, что не влияет на пользователя напрямую#591 открыл
8 марта 2021 г.автором пчела-сан
1 из 4 задач
Поддержка анаграммы? улучшение
Новая функция или запросНовый декодер
Для новых декодеров/расшифровщиков!№ 584 открыт 9 февраля 2021 г. автором Redst0neFlux
JWT-заголовок и декодирование полезной нагрузки (base64 с точками) улучшение
Новая функция или запросfeature_request
#489
открыт 9 октября 2020 г. автором
хорошо21
автором
хорошо21
Совет! Найдите все открытые проблемы с текущими разработками с помощью linked:pr.
Служба расшифровки ИИ
От: Innovation, Science and Economic Development Canada
Королевская конная полиция Канады (RCMP) ищет решение с искусственным интеллектом (ИИ), которое поможет легально получить доступ к зашифрованным данным.
Спонсор Challenge:
Королевская канадская конная полиция (RCMP)
Механизм финансирования:
Контракт
Дата открытия:
ноябрь 4, 2021
Войдите в систему для просмотра представленных материалов
Пожалуйста, ознакомьтесь с уведомлением о тендере для этого испытания на сайте «Купить и продать».
Вызов
Постановка проблемы
RCMP вместе со всеми канадскими правоохранительными органами в настоящее время сталкивается с дилеммой преступников, использующих сложное шифрование для обхода или иного предотвращения законного доступа следователей к данным, изъятым в ходе уголовных расследований.
Использование этих методов шифрования лицами, участвующими в незаконных действиях, значительно снижает риск судебного преследования. Общеизвестно, что полиция может получить судебное разрешение на обыск устройства, но она не может заставить человека предоставить пароль. Этот сценарий сильно стимулирует людей использовать ту или иную форму шифрования для всех своих данных в качестве вторичной страховки от судебного преследования.
КККП занимается разработкой системы искусственного интеллекта, которая может поглощать материалы, изъятые во время расследования, и генерировать списки слов для конкретных случаев, которые будут использоваться при попытке расшифровать изъятые данные. Этот ИИ должен иметь возможность принимать и обрабатывать файлы криминалистических данных в качестве исходного материала.
Желаемые результаты и соображения
Основные (обязательные) результаты
Предлагаемые решения должны:
- Принимать и обрабатывать материалы любого размера из распространенных типов криминалистических файлов. например e01, ad1, дд, ex01.
- Создание тематических списков слов паролей на основе активности пользователя с данными, интересов пользователя и паролей, обнаруженных на пропущенных криминалистических изображениях.
- Обработка истории веб-поиска из обычных веб-браузеров. например Хром, Эдж, Фаерфокс, Сафари.
- Обработка общих документов. например MS Word, MS Excel, текстовые файлы, Adobe.
- Экспорт производных паролей в текстовом формате для использования в программах расшифровки.
 например e01, ad1, дд, ex01.
например e01, ad1, дд, ex01.Дополнительные результаты
Предлагаемые решения должны:
- Идентифицировать распространенные зашифрованные файлы из образов устройств. например luks, bitlocker, truecrypt и т. д.
- Ввод известных паролей в базу данных и использование этой базы данных для создания производных паролей.
- Предоставляет удобный графический интерфейс пользователя (GUI).
- Инициировать задания по расшифровке, используя сгенерированные списки паролей с помощью обычного программного обеспечения для расшифровки. например Элкомсофт, Passware, Hashcat и др.
 например Элкомсофт, Passware, Hashcat и др.
например Элкомсофт, Passware, Hashcat и др.Предыстория и контекст
Это универсальная проблема, с которой сталкиваются в Канаде и на международном уровне союзники, связанные с легальным доступом к зашифрованным данным. Все федеральные, провинциальные и муниципальные правоохранительные и регулирующие органы в Канаде постоянно пытаются взломать зашифрованные данные, чтобы получить законный доступ к их содержимому.
Нынешний метод использования массовых систем дешифрования и попытки подбора пароля очень неэффективны и в целом редко бывают успешными. Стандартная практика частных лиц, использующих шифрование, растет во всем мире, так как это становится единственным наиболее эффективным методом, позволяющим заблокировать уголовные расследования. Эта задача направлена на использование инноваций государственного сектора для решения этой проблемы, поскольку она может помочь другим федеральным агентствам, таким как Агентство пограничной службы Канады, Министерство обороны, Министерство рыболовства и океанов, Канадская комиссия по радио, телевидению и телекоммуникациям и Канадское налоговое агентство. .
.
Интересные статьи:
- https://www.cbc.ca/news/politics/lucki-briefing-binde-cybercrime-1.4831340
- https://cippic.ca/uploads/ATI-RCMP- Encryption_and_Law_Enforcement-2016.pdf
Максимальная стоимость контракта и поездки
В результате этого вызова может быть заключено несколько контрактов.
Этап 1:
- Максимальное финансирование, доступное для любого контракта Этапа 1, вытекающего из этого Конкурса, составляет : 150 000 канадских долларов без учета применимых налогов, расходов на доставку, проезд и проживание, если это необходимо.
- Максимальный срок действия любого контракта Этапа 1, заключенного в результате этого Конкурса, составляет до 6 месяцев (исключая представление окончательного отчета).
- Предполагаемое количество контрактов на Этапе 1: 2
Этап 2:
Примечание . Только отвечающие требованиям компании, успешно завершившие Этап 1, будут приглашены для подачи заявки на Этап 2.
- Максимальное финансирование, доступное для стоимость любого контракта Этапа 2, вытекающего из этого Конкурса, составляет: 1 000 000 канадских долларов без учета применимых налогов, расходов на доставку, проезд и проживание по мере необходимости.
- Максимальный срок действия любого контракта Этапа 2, вытекающего из этого Конкурса, составляет до 24 месяцев (за исключением представления окончательного отчета).
- Расчетное количество контрактов на этапе 2: 1
Это раскрытие сделано добросовестно и не обязывает Канаду заключать какие-либо контракты на общее приблизительное финансирование. Окончательные решения о количестве грантов на Этапе 1 и Этапе 2 будут приниматься Канадой на основе таких факторов, как результаты оценки, приоритеты ведомства и наличие средств. Канада оставляет за собой право предоставлять частичные вознаграждения и вести переговоры об изменении объема проекта.
Примечание: Выбранные компании имеют право на получение одного контракта на каждом этапе каждого испытания.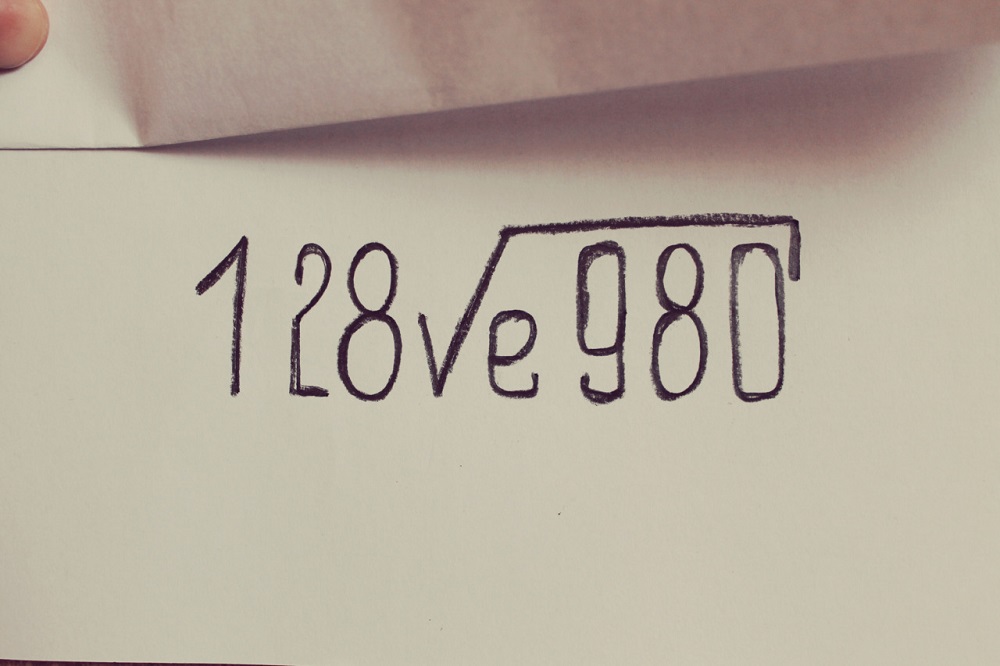
Поездки
В связи с ограничениями, связанными с Covid-19, стартовое совещание и заключительное обзорное совещание могут проходить в формате видео или телеконференции.
Вводное совещание
Телеконференция/видеоконференция
Совещание(я) по обзору прогресса
Телеконференция/видеоконференция
Итоговое обзорное совещание
Телеконференция/видеоконференция
Все остальные виды связи могут осуществляться по телефону, видеоконференции и WebEx.
Право на участие
Предложения по решению могут быть поданы только малым бизнесом, который соответствует всем следующим критериям:
- для получения прибыли
- зарегистрирован в Канаде (на федеральном или провинциальном уровне)
- 499 или меньше эквивалент полной занятости (FTE) сотрудники Сноска **
- научно-исследовательская деятельность, проводимая в Канаде
- 50% или более его годовой заработной платы в настоящее время выплачивается сотрудникам и подрядчикам, которые проводят большую часть своего времени, работая в Канаде Сноска **
- обычное место работы Сноска **
- 50% или более руководителей высшего звена (вице-президент и выше) имеют Канаду в качестве основного места жительства Сноска **
Критерии оценки
Официальным источником Критериев оценки для этой задачи является Государственная электронная система торгов (покупка и продажа) https://buyandsell. gc.ca/procurement-data/tender-notice/PW-20-00899125)
gc.ca/procurement-data/tender-notice/PW-20-00899125)
В в случае расхождения между приведенной ниже информацией и информацией, опубликованной на сайтах «Купить и продать», «Купить и продать», будет иметь приоритет.
Участник торгов должен заполнить Электронную форму подачи заявки на участие в конкурсе, указав информацию, достаточную для того, чтобы Канада могла оценить предложение в соответствии с критериями и Схемой оценки. Информация должна демонстрировать, насколько предложение соответствует критерию.
Часть 1: Обязательные критерии
Предложения должны соответствовать всем обязательным критериям, определенным при достижении «Пройдено», чтобы перейти к Части 2. Предложения, которые не соответствуют всем обязательным критериям, будут считаться не отвечающими требованиям и не подлежат дальнейшему рассмотрению.
Обязательные критерии
(предложение участника торгов должно быть адресовано)
Вопрос 1 a: Объем
Опишите предлагаемое решение и продемонстрируйте, как оно отвечает на вызов. Включите в свое описание научную и технологическую основу, на которой предлагается решение, и четко продемонстрируйте, как решение отвечает всем Essential Outcomes (если указано) в разделе «Желаемые результаты» в Уведомлении о вызове.
Включите в свое описание научную и технологическую основу, на которой предлагается решение, и четко продемонстрируйте, как решение отвечает всем Essential Outcomes (если указано) в разделе «Желаемые результаты» в Уведомлении о вызове.
Схема оценки (Обязательно – Пройдено/Не пройдено)
Пройдено
Предлагаемое Участником торгов решение четко сформулировано, находится в рамках задачи и касается всех основных результатов (если они указаны) в Уведомлении о вызове.
Сбой
Предлагаемое решение сформулировано как выходящее за рамки задачи.
ИЛИ
В предложении четко не показано, как предлагаемое решение обеспечивает достижение всех основных результатов, перечисленных в задании.
OR
Предложенное решение плохо описано и не допускает конкретного анализа.
ИЛИ
Практически отсутствуют научные и/или технологические доказательства того, что предлагаемое решение может решить эту проблему.
Вопрос 2: Текущий уровень технологической готовности (TRL)
- Укажите текущий TRL предлагаемого решения. (Раскрывающееся меню электронной формы отправки Challenge Stream)
- Опишите научно-исследовательские и опытно-конструкторские работы, которые были проведены для доведения предлагаемого решения до заявленного TRL.
 (Раскрывающееся меню электронной формы отправки Challenge Stream)
(Раскрывающееся меню электронной формы отправки Challenge Stream)Схема оценки (Обязательно — Пройдено/Не пройдено)
Пройдено
Участник торгов продемонстрировал, что предлагаемое решение в настоящее время находится между TRL 1 и 6 (включительно), и представил обоснование, пояснив исследования и разработки (НИОКР). предпринятое для приведения решения к заявленному TRL.
Неудовлетворительно
Участник торгов не представил достаточных доказательств того, что текущий TRL находится в диапазоне от 1 до 6 (включительно), включая:
- Недостаточно/отсутствуют доказательства для решения TRL.
- Решение предполагает разработку фундаментальных или фундаментальных исследований.
- Решение демонстрируется при TRL 7 или выше.
- Недостаточное/неясное/отсутствие обоснования, объясняющего НИОКР, которые были проведены для доведения решения до заявленного TRL.
- Объяснение просто перефразирует описание данного уровня TRL.

Вопрос 3a: Инновация
Продемонстрируйте, как предлагаемое решение соответствует одному или нескольким из приведенных ниже определений инновации ISC:
- Изобретение*, новая технология или новый процесс, которых в настоящее время нет на рынке.
- Значительные изменения в применении существующих технологий/компонентов/процессов, которые применяются в условиях или условиях, при которых текущие приложения невозможны или неосуществимы.
- Улучшение функциональности, стоимости или производительности по сравнению с существующей технологией/процессом, которые считаются современными или лучшими в отрасли.
* «Изобретение» определяется для целей ISC как: «Производственная конструкция или любое другое новое и полезное усовершенствование, которое является новым или новаторским, то есть не является общеизвестным или не является очевидным производным от существующего способа делать вещи. »
»
Схема оценки (Обязательно — Пройдено/Не пройдено)
Pass
Участник торгов продемонстрировал, что предлагаемое решение соответствует одному или нескольким определениям инноваций ISC.
Неудовлетворительно
Участник торгов не представил достаточных доказательств того, что текущий TRL находится в диапазоне от 1 до 6 (включительно), включая:
- Участник торгов не представил достаточных доказательств того, что предлагаемое решение соответствует любому из определения инноваций; OR
- Участник торгов продемонстрировал, что предлагаемое решение является постепенным улучшением, «хорошим проектированием» или технологией, которая будет развиваться в обычном ходе разработки продукта (т. е. следующей версии или выпуска).
Вопрос 3b: Преимущество современных технологий
Подробно опишите конкурентные преимущества и уровень развития по сравнению с существующими технологиями. Там, где это уместно, назовите существующие технологии, а также потенциальные заменители или конкурентов.
Чтобы продемонстрировать это, предложения должны включать следующую информацию:
- Улучшения (незначительные или существенные) по сравнению с существующими технологиями или заменами. Используйте прямое сравнение.
- Каким образом предлагаемая инновация создаст конкурентные преимущества в существующих рыночных нишах или рыночных пространствах.
Схема оценки (обязательные критерии – Пройдено/Не пройдено + Баллы)
0 баллов/Не пройдено:
- Участник торгов не продемонстрировал, что предложенное решение превосходит существующие технологии, включая доступные конкурирующие решения; OR
- Предлагаемое решение минимально улучшает текущий уровень техники, но недостаточно для создания конкурентных преимуществ в существующих рыночных нишах; ИЛИ
- Заявленные достижения описаны в общих чертах, но не подтверждены конкретными измеримыми данными.
5 баллов/Pass:
- Участник торгов продемонстрировал, что предлагаемое решение предлагает одно или два незначительных усовершенствования существующих технологий, включая доступные конкурирующие решения, которые могут создать конкурентные преимущества в существующих рыночных нишах.

12 баллов/проход
- Участник торгов продемонстрировал, что предлагаемое решение предлагает три или более незначительных усовершенствования существующих технологий, включая доступные конкурирующие решения, которые вместе могут создать конкурентные преимущества в существующих рыночных нишах; ИЛИ
- Участник торгов продемонстрировал, что предложенное решение предлагает одно существенное усовершенствование существующих технологий, которое может создать конкурентные преимущества в существующих рыночных нишах
20 баллов/Pass:
- Участник торгов продемонстрировал, что предлагаемое решение предлагает два или более существенных улучшения существующих технологий, включая доступные конкурирующие решения, которые, вероятно, создадут конкурентные преимущества в существующих рыночных нишах и могут определить новые рыночные пространства; OR
- Участник торгов продемонстрировал, что предлагаемое решение можно считать новым эталоном современного уровня техники, который явно опережает конкурентов и который, вероятно, определит новые рыночные пространства
Часть 2: Критерии выставления баллов
Предложения должны соответствовать общему минимальному проходному баллу в 50%, чтобы считаться отвечающими требованиям. Предложения, не набравшие минимального проходного балла, будут объявлены не отвечающими требованиям и не будут рассматриваться дальше.
Предложения, не набравшие минимального проходного балла, будут объявлены не отвечающими требованиям и не будут рассматриваться дальше.
Критерии начисления баллов
(предложение участника торгов по адресу)
Вопросы и ответы
Пожалуйста, обратитесь к извещению о тендере для этого вызова на покупку и продажу.
Все входящие вопросы, касающиеся этой конкретной задачи, следует направлять по адресу [email protected]
Вы также можете ознакомиться с часто задаваемыми вопросами о программе Innovative Solutions Canada.
Также доступен глоссарий.
Древний язык не поддается расшифровке уже 100 лет. Может ли ИИ взломать код?
Цзямин Луо вырос в материковом Китае, думая о забытых языках. Когда он был моложе, он задавался вопросом, почему разные языки, на которых говорили его мать и отец, часто смешивали вместе как китайские «диалекты».
Когда в 2015 году он стал докторантом компьютерных наук в Массачусетском технологическом институте, его интерес столкнулся с давним увлечением его наставника древними письменами. В конце концов, что может быть более запущенным — или, используя более академический термин Луо, «менее обеспеченным ресурсами», чем давно потерянный язык, оставленный нам в виде загадочных символов на разрозненных фрагментах? «Я считаю эти языки загадками», — сказал Луо Остальному миру через Zoom. «Это определенно то, что меня в них привлекает».
В конце концов, что может быть более запущенным — или, используя более академический термин Луо, «менее обеспеченным ресурсами», чем давно потерянный язык, оставленный нам в виде загадочных символов на разрозненных фрагментах? «Я считаю эти языки загадками», — сказал Луо Остальному миру через Zoom. «Это определенно то, что меня в них привлекает».
В 2019 годуЛуо попал в заголовки газет, когда, работая с командой коллег-исследователей из Массачусетского технологического института, применил свои знания в области машинного обучения для расшифровки древних письменностей. Он и его коллеги разработали алгоритм, основанный на закономерностях изменения языков с течением времени. Они скормили своим алгоритмам слова на потерянном языке и на известном родственном языке; его задача заключалась в том, чтобы сопоставить слова утраченного языка с их аналогами в известном языке. Важно отметить, что один и тот же алгоритм можно применять к разным языковым парам.
Луо и его коллеги проверили свою модель на двух древних письмах, которые уже были расшифрованы: угаритском, родственном иврите, и линейном письме Б, впервые обнаруженном среди руин эпохи бронзового века на греческом острове Крит. Эпиграфистам-профессионалам и любителям — людям, изучающим древнюю письменность, — потребовалось почти шесть десятилетий мысленных споров, чтобы расшифровать линейное письмо Б. Официально 30-летнему британскому архитектору Майклу Вентрису в первую очередь приписывают его расшифровку, хотя частные усилия классика Алисы Кобер заложил основу для своего прорыва. Сидя ночь за ночью за своим обеденным столом в Бруклине, штат Нью-Йорк, Кобер собрала импровизированную базу данных символов линейного письма Б, состоящую из 180 000 бумажных полосок, хранящихся в папиросных коробках, и использовала их, чтобы сделать важные выводы о характере письма. Она умерла в 1950, за два года до того, как Вентрис взломал код. Линейное письмо B теперь признано самой ранней формой греческого языка.
Эпиграфистам-профессионалам и любителям — людям, изучающим древнюю письменность, — потребовалось почти шесть десятилетий мысленных споров, чтобы расшифровать линейное письмо Б. Официально 30-летнему британскому архитектору Майклу Вентрису в первую очередь приписывают его расшифровку, хотя частные усилия классика Алисы Кобер заложил основу для своего прорыва. Сидя ночь за ночью за своим обеденным столом в Бруклине, штат Нью-Йорк, Кобер собрала импровизированную базу данных символов линейного письма Б, состоящую из 180 000 бумажных полосок, хранящихся в папиросных коробках, и использовала их, чтобы сделать важные выводы о характере письма. Она умерла в 1950, за два года до того, как Вентрис взломал код. Линейное письмо B теперь признано самой ранней формой греческого языка.
Луо и его команда хотели проверить, сможет ли их модель машинного обучения дать тот же ответ, но быстрее. Алгоритм показал то, что было названо «поразительной точностью»: он смог правильно перевести 67,3% слов линейного письма Б в их современные греческие эквиваленты. По словам Луо, на запуск алгоритма после его создания ушло от двух до трех часов, что сократило дни или недели — месяцы или годы, — которые могут потребоваться для ручной проверки теории путем перевода символов один за другим. Результаты для угаритского языка показали улучшение по сравнению с предыдущими попытками автоматической дешифровки.
По словам Луо, на запуск алгоритма после его создания ушло от двух до трех часов, что сократило дни или недели — месяцы или годы, — которые могут потребоваться для ручной проверки теории путем перевода символов один за другим. Результаты для угаритского языка показали улучшение по сравнению с предыдущими попытками автоматической дешифровки.
Работа выдвинула интригующее предложение. Может ли машинное обучение помочь исследователям в их стремлении взломать другие, еще не расшифрованные письмена — те, которые до сих пор сопротивлялись любым попыткам перевода? Какие исторические тайны могут быть раскрыты в результате?
Британская Индия, 1872-1873 гг. Александр Каннингем, инженер английской армии, ставший геодезистом-археологом, слонялся по руинам города в провинции Пенджаб, который местные жители называли Хараппа. На первый взгляд, исследовать было нечего: около двух десятилетий назад инженеры, работавшие над соединением городов Лахор и Мултан, наткнулись на это место и использовали многие из найденных кирпичей — прекрасно сохранившихся, обожженных на огне — в качестве балласта для почти 100 миль железнодорожных путей, беспечно не подозревая, что они являются остатками одной из древнейших цивилизаций в мире.
Каннингем тоже этого не знал — цивилизация долины Инда не была официально «открыта» до 1920-х годов, — но он знал, что это место имеет или историческую ценность. Копаясь в руинах, он и его команда наткнулись на каменные орудия, которые, как они предположили, использовались для соскабливания дерева или кожи. Они собрали осколки древней глиняной посуды и что-то похожее на глиняный ковш. Однако самым поразительным открытием стала крошечная каменная табличка размером примерно 1,5 на 1,5 дюйма. «На нем очень глубоко выгравирован бык, без горба, смотрящий вправо, с двумя звездами под шеей», — писал Каннингем в своем отчете. «Над быком есть надпись из шести знаков, которые мне совершенно неизвестны. Это определенно не индийские буквы; а так как сопровождающий их бык без горба, я заключаю, что тюлень чужой для Индии».
У меня есть дешевая копия этой первой печати, купленная много лет назад в музейном сувенирном магазине в одном из мест долины Инда: у животного на ней толстая шея, люмпеническое туловище и единственный парящий рог. Некоторые утверждают, что это единорог. Надпись, нацарапанная над ним, напоминает строку иероглифов; один персонаж похож на рыбу. За полтора века, прошедшие с момента открытия первой печати, были обнаружены еще тысячи: 90% из них вдоль реки Инд на территории современного Пакистана, остальные — в Индии или даже на территории современного Ирака.
Некоторые утверждают, что это единорог. Надпись, нацарапанная над ним, напоминает строку иероглифов; один персонаж похож на рыбу. За полтора века, прошедшие с момента открытия первой печати, были обнаружены еще тысячи: 90% из них вдоль реки Инд на территории современного Пакистана, остальные — в Индии или даже на территории современного Ирака.
Теперь мы знаем, что эти таблички, описанные одним археологом как «маленькие шедевры контролируемого реализма», являются коренными жителями Индийского субконтинента; исследователи полагают, что они, вероятно, использовались для закрытия документов и маркировки упаковок товаров, поэтому их называют пломбами. Исследователи пришли к выводу, что отчасти из-за того, что символы в надписях толкают друг друга с одного конца, как если бы у надписавшего не хватило места, надписи следует читать справа налево. Но мы до сих пор не знаем, что они на самом деле скажем .
Каменный штамп-печать, найденный в Хараппе в долине Инда, на территории современных пакистанских провинций Пенджаб и Синд. Попечители Британского музея
Попечители Британского музеяЭто не из-за отсутствия попыток. Ученые часто отмечают, что письменность Инда, поскольку известно собрание примерно 4000 раскопанных надписей, содержащих от 400 до примерно 700 уникальных символов, может быть одним из 90 525 наиболее 90 526 расшифрованных письменностей в истории. С 19 века опубликовано более ста попыток.20 с. Одна теория связывает его с письмом Ронгоронго острова Пасхи, также до сих пор не расшифрованным; другой, предложенный немецким тантрическим гуру, утверждающим, что нашел свое решение с помощью медитации, связывает его с клинописью, использовавшейся для письма на шумерском языке.
Для некоторых групп в Южной Азии поиски расшифровки письма Инда почти экзистенциальны. Индия и Пакистан, все больше и больше раздираемые соответствующими проявлениями религиозного национализма, заметно различаются по отношению к своему общему древнему прошлому. Пакистанское государство, глубоко привязанное к идее себя как мусульманской родины, в значительной степени игнорирует свое доисламское наследие; его индийский коллега, с другой стороны, занялся изучением истории, чтобы найти оправдание утверждению, что Индия всегда была индуистской нацией.
Вплоть до открытия Хараппы считалось, что первыми индейцами были люди, жившие между 1500 и 500 годами до н.э. и составил Веды, тексты на санскрите, которые составляют основу современного индуизма. Открытие цивилизации людей, живших с 90 525 до 90 526 ведических людей, перевернуло историю Индии. Учитывая, что это подрывает их претензии на коренное происхождение, сторонники хиндутвы — наиболее распространенного направления индуистского национализма — отвергают теорию доведической цивилизации, даже несмотря на то, что свидетельства в ее пользу накапливаются в различных дисциплинах, включая археологию, генетику и лингвистику.
Таким образом, малейшие достижения в исследованиях долины Инда имеют тенденцию распространяться далеко за пределы научных кругов. Попытки доказать, что жители Инда поклонялись индуистским богам и говорили на более ранней форме санскрита, не ослабевают. В 2000 году один исследователь даже исказил в цифровой форме изображение индской печати, чтобы животное на нем выглядело как лошадь, которая часто фигурирует в санскритской литературе.
Если оставить в стороне политику, то удивительно, как мало мы знаем о коренных жителях долины Инда, которые когда-то составляли почти 10% населения мира. Это особенно досадно, учитывая, насколько больше мы знаем об их современниках, таких как люди египетской и месопотамской цивилизаций. Одной из причин этого является продолжающаяся неуловимость письма Инда.
Настроить машины на для работы со сценарием Инда сложнее, чем использовать их для обратного проектирования линейного письма Б. У нас не так много информации о сценарии Инда: самое главное, мы не знаем, что еще язык, с которым это может быть связано. В результате такая модель, как у Луо, не годилась для письма Инда. Однако это не значит, что технологии не могут помочь. В некотором смысле компьютерное моделирование уже сыграло решающую роль: оно показало, что письменность Инда вообще является языком.
На протяжении большей части 20-го века индусские надписи были широко признаны как изображения нерасшифрованного языка. Затем, в 2004 году, группа гарвардских исследователей — культуролог-нейробиолог и сравнительный историк Стив Фармер, теоретик вычислений Ричард Спроат и филолог Майкл Витцель — опубликовала статью, в которой, по сути, опровергались почти все существующие исследования по этому вопросу. Они утверждали, что печати Инда были не чем иным, как набором религиозных или политических символов — подобных, скажем, дорожным знакам, — и все попытки расшифровать их как язык были пустой тратой времени. Чтобы подчеркнуть свою точку зрения, Фармер предложил вознаграждение в размере 10 000 долларов любому, кто сможет найти надпись Инда, содержащую не менее 50 символов.
Затем, в 2004 году, группа гарвардских исследователей — культуролог-нейробиолог и сравнительный историк Стив Фармер, теоретик вычислений Ричард Спроат и филолог Майкл Витцель — опубликовала статью, в которой, по сути, опровергались почти все существующие исследования по этому вопросу. Они утверждали, что печати Инда были не чем иным, как набором религиозных или политических символов — подобных, скажем, дорожным знакам, — и все попытки расшифровать их как язык были пустой тратой времени. Чтобы подчеркнуть свою точку зрения, Фармер предложил вознаграждение в размере 10 000 долларов любому, кто сможет найти надпись Инда, содержащую не менее 50 символов.
Большинство индологов и других исследователей письменности Инда отвергли эти аргументы. Однако одна группа математиков обратилась к компьютерам, чтобы исследовать утверждения. Ронохой Адхикари, профессор статистической физики Кембриджского университета, был одним из них.
До Кембриджа Адхикари работал в Институте математических наук в Ченнаи. В 2009 году он посетил выступление Ираватама Махадевана, индийского государственного служащего, ставшего эпиграфистом. Махадеван, умерший в 2018 году, уже взломал тамил-брахми, еще одну нерасшифрованную письменность, а затем обратил свое внимание на письменность Инда.
В 2009 году он посетил выступление Ираватама Махадевана, индийского государственного служащего, ставшего эпиграфистом. Махадеван, умерший в 2018 году, уже взломал тамил-брахми, еще одну нерасшифрованную письменность, а затем обратил свое внимание на письменность Инда.
Адхикари вспоминает, как был очарован. «Я человек из науки; У меня нет гуманитарного образования», — сказал он. «Но что мне показалось очень привлекательным во взгляде Махадевана на проблему, так это то, что у него был очень количественный, почти научный подход. Он спрашивал, сколько раз встречается тот или иной символ? На фоне чего это происходит? Каков контекст, в котором это происходит? И мне казалось, что, поскольку это уже было определено количественно, было бы легко перевести это в формальный математический анализ».
Несколько других специалистов по данным присоединились к Адхикари. Они знали, что не могут расшифровать сценарий. «Итак, мы задали вопрос: можем ли мы хотя бы сказать, передает ли он какую-либо лингвистическую информацию?»
«Итак, мы задали вопрос: можем ли мы хотя бы сказать, передает ли он какую-либо лингвистическую информацию?»
Под руководством ученого-компьютерщика Раджеша Рао исследователи разработали компьютерную программу, чтобы посмотреть, смогут ли они ответить на вопрос: была ли письменность Инда языком? «Вы можете дать мне любую последовательность символов, мне все равно, какие они — иероглифы, письменность, ноты, компьютерный код — и я посмотрю на них с точки зрения математика», — объяснил Адхикари. «Это означает, что я просто посчитаю, сколько раз один знак встречается рядом с другим».
«Итак, мы задали вопрос: можем ли мы хотя бы сказать, передает ли он какую-либо лингвистическую информацию?»
Их программа основывалась на работе Клода Э. Шеннона, американского математика середины века, инженера и дешифратора кодов военного времени, который сформулировал понятие информационной энтропии — по сути, математической меры беспорядка. В лингвистических системах символы встречаются с несколько фиксированной частотой. «Например, я просто не могу взять букву из алфавита, соединить ее с другой буквой из алфавита и ожидать, что получится английское слово», — объяснил Адхикари. Например, в обычном английском языке за буквой «q» почти всегда следует «u». Эта полугибкость является признаком всех языковых систем. Компьютерный же код совершенно негибок: малейшее отклонение, и он развалится.
«Например, я просто не могу взять букву из алфавита, соединить ее с другой буквой из алфавита и ожидать, что получится английское слово», — объяснил Адхикари. Например, в обычном английском языке за буквой «q» почти всегда следует «u». Эта полугибкость является признаком всех языковых систем. Компьютерный же код совершенно негибок: малейшее отклонение, и он развалится.
Исследователи загрузили в свою программу 4000 надписей, которые составляют всю письменность Инда. На всякий случай они также запустили программу на других лингвистических образцах (английские символы и слова, санскрит, тамильский, шумерский и тагальский) и некоторых нелингвистических сценариях (ДНК, белок, Соната Бетховена № 32 и компьютерный код под названием Fortran). . Программа длилась около 45 минут.
«Я помню, как впервые был создан этот сюжет, — вспоминает Адхикари. На графике кривые, изображающие музыку, белки и последовательности ДНК, зависли высоко, близко к максимальному уровню энтропии, что указывает на высокий уровень случайности. Ниже все известные языки собраны в тесный кластер. Фортран появляется ниже.
На графике кривые, изображающие музыку, белки и последовательности ДНК, зависли высоко, близко к максимальному уровню энтропии, что указывает на высокий уровень случайности. Ниже все известные языки собраны в тесный кластер. Фортран появляется ниже.
Что касается письма Инда, то оно появляется вместе с другими языками, сразу после санскрита и почти полностью соответствует тамильскому. «Это было фантастически. Это действительно было очень хорошо. Приятно иметь догадку, но иметь возможность ее доказать — я помню, как подумал: «Да, у нас действительно что-то есть».
Конечно, существует большая разница между демонстрацией того, что сценарий кодирует язык, и декодированием того, что он говорит.
Бахата Ансумали Мукхопадхьяй встретил Адхикари более десяти лет назад. В то время она была разочарованным разработчиком программного обеспечения, ищущим выход. Когда Адхикари, которая начала изучать методы глубокого обучения для работы над сценарием, искала помощника, она с радостью вызвалась.
Глубокое обучение сегодня является доминирующей технологией искусственного интеллекта. Это в первую очередь форма распознавания образов: чем больше данных вы передаете машине, тем лучше она интерпретирует будущие данные. Но подход с большими наборами данных не особенно полезен, когда речь идет о предметах с низким уровнем ресурсов (если использовать термин Луо), таких как письменность Инда, где данные ограничены. Мукхопадхьяй быстро понял это.
— Я должна была программировать, — застенчиво сказала она. — Но большую часть времени я проводил за чтением.
Мукхопадхьяй спускался в одну кроличью нору за другой. Она анализировала месопотомские, аккадские, шумерские и древнеперсидские словари. Она сама научилась читать египетские иероглифы. «Я поняла, насколько тонким может быть символизм», — сказала она. «Как и у бога Гора, его глаз был разорван на осколки. Каждая часть представляется как дробь, а затем древние египтяне создали свои символы для дробей».
«Здесь вам нужно понять историческую символику, используемую в Индии.
 Как искусственный интеллект справится с этим?»
Как искусственный интеллект справится с этим?»Несмотря на то, что она помогала создавать программное обеспечение для исследования письменности Инда, ее сомнения относительно подхода росли. «Понимаете, если бы индусское письмо было альфа-слоговым письмом [система письма, разделенная на единицы согласных и гласных, как в урду/хинди], тогда машинное обучение и искусственный интеллект были бы очень подходящими», — объяснила она. Но поскольку надписи кажутся графическими по своей природе, они представляли большую проблему. «Здесь вы должны понимать историческую символику, используемую в Индии. Как искусственный интеллект справится с этим? Откуда ИИ мог знать, что эти символы представляют фрагменты глаза Гора?»
В течение последних нескольких лет Мукхопадхьяй самостоятельно исследовал надписи Инда, сосредоточив внимание на отдельных символах. Это включает в себя выдвижение определенной теории, а затем ее проверку — в этом компьютеры не очень хороши.
Бахата Ансумали Мукхопадхьяй, исследователь письменности Инда. Тим Данк для остального мира
Тим Данк для остального мираТеория Мухопадхьяй, которую она обосновала в рецензируемой статье в журналах Nature, , заключается в том, что печати Инда использовались для налогообложения и торгового контроля — например, коллекционер мог носить одну из них в качестве своего рода лицензии. В последующей статье, исследуя слова, используемые для «слона» — piri, piru, pilu — и «слоновая кость» — pirus — на ближневосточных языках во времена цивилизации Инда, она утверждала, что люди Инда говорили на более ранней форме дравидийского языка, лингвистического предка современных языков, таких как Телугу, тамильский и каннада. Если исследователи смогут успешно определить современное лингвистическое отношение к письменности Инда, это может стать ключом к его расшифровке. Когда Мукхопадхьяй объясняет свою работу, ее серьги звенят. Это искусные изображения голов слонов. Пилу , — сказала она, улыбаясь.
«Я думаю, что есть много аспектов познания, которые мы не можем закодировать в удобной форме».

Текущие версии ИИ не предназначены для развертывания подхода, принятого Мухопадхьяем. Адхикари, который теперь также менее оптимистичен в отношении перспективы машинного дешифрования, скептически относится к тому, что это когда-либо будет. «Я думаю, что есть много аспектов познания, которые мы не можем закодировать в удобной форме», — сказал он. «Я бы не рискнул предположить, но я не думаю, что это произойдет в моей жизни. Я думаю, нам нужно лучше понять свой мозг». Более того, добавил он, не вся информация поддается количественной оценке, которую могут понять компьютеры. «Машина очень хорошо понимает раз, два, три. Два плюс два равно четырем, да. Но… — Его взгляд переместился за пределы экрана компьютера. «Но то, что этот закат здесь выглядит как красивое пламя — именно такая абстракция держит ключ к этому сценарию».
Независимо от используемого подхода ИИ зависит от наличия высококачественных данных в машиночитаемом формате. Это остается ключевой проблемой, когда речь идет о древних текстах, учитывая, что они часто доходят до нас с надрывами, размытыми или неполными в какой-либо другой форме. Ученые могут десятилетиями спорить об уникальности символов: например, это царапина рядом с известным символом или вообще новый символ? Учитывая, как мало нужно работать с давно утерянными языками, зашумленные или неполные данные могут серьезно сократить усилия по расшифровке.
Ученые могут десятилетиями спорить об уникальности символов: например, это царапина рядом с известным символом или вообще новый символ? Учитывая, как мало нужно работать с давно утерянными языками, зашумленные или неполные данные могут серьезно сократить усилия по расшифровке.
В течение последних двух десятилетий Брайан К. Уэллс из Ванкувера и Андреас Фулс из Берлина незаметно оцифровывали все известные печати и символы Инда. Они добавляют контекстную информацию — например, где они были раскопаны, когда и с какими артефактами — и добавляют новые по мере их раскопок. Интерактивный корпус текстов Инда (ICIT) в настоящее время содержит информацию о 4 537 артефактах с надписями, 5 509 текстах и 19 616 случаях появления знаков, содержащих в общей сложности 707 уникальных символов Инда — гораздо больше, чем 417 ранее идентифицированных.
Штамп-печать из глазурованного белого стеатита с изображением быка, стоящего над яслями, найдена в Вавилоне, Ирак. Попечители Британского музея Более ранние корпуса компилировались вручную. В результате, утверждает Уэллс, они были настолько ограничены, что рисковали подорвать исследования сценариев. «Вы знаете старую компьютерную поговорку, — сказал он недавно по скайпу, — мусор на входе, мусор на выходе». В настоящее время базу данных используют около 50 исследователей по всему миру.
В результате, утверждает Уэллс, они были настолько ограничены, что рисковали подорвать исследования сценариев. «Вы знаете старую компьютерную поговорку, — сказал он недавно по скайпу, — мусор на входе, мусор на выходе». В настоящее время базу данных используют около 50 исследователей по всему миру.
На данный момент тайны письменности Инда продолжают ускользать от расшифровки. В прошлом году в последующей работе по автоматизации декодирования угаритского и линейного письма Б Луо и его команда сделали небольшой, но важный шаг вперед: алгоритм, направленный на выявление возможных родственных языков нерасшифрованных систем письма. Потенциально это могло бы помочь решить проблему расшифровки сценариев, для которых еще нет известного языка, с которым их можно было бы сравнить. Когда Луо и его команда проверили свою модель на иберийском языке, который исторически был связан с баскским, их результаты показали, что эти два языка на самом деле не были достаточно близки, чтобы быть родственными — вывод, который подтвердил недавние исследования по этому вопросу.
Но в то время как в иберийском языке, по словам Луо, не менее 80 уникальных символов, в индусском письме их не менее 400, что делает его экспоненциально более сложным. Тем не менее, теоретически, современные машины могут справиться с этим уровнем вычислений. Можно ли просто «грубым методом» решить такую проблему, как письменность Инда, — проанализировать ее на фоне всех современных языков Южной Азии и посмотреть, какой из них окажется наиболее близким лингвистическим родством? — Хорошая мысль, — сказал Луо, задумавшись. «Если бы у меня было время, я бы обязательно попробовал это».
Луо тут же отмечает, что он не ожидает, что расшифровка утерянных языков будет полностью автоматизирована. «Я думаю так: пусть система предложит список кандидатов и пусть эксперты увидят: «Хорошо, может быть, эта теория более верна, чем другая», — сказал он. «Это определенно снижает усилия и количество часов, которые приходится тратить экспертам».
Не все готовы принимать помощь машин.